oo oo oo 20230824
OO ,oOOo. oOOooo oOOooo ,oOOo. ,oOOOo
OO OO OO OO OO OO OO OO.. THIS IS FICTITIOUS, FROM FICTIONAL PERSONA, NO IDENTIFICATION WITH ACTUAL
OO. OO OO OO. OO. OO"""' `"""OO PEOPLE|PRODUCTS|EMPLOYERS|BUSINESSES IS INTENDED OR SHOULD BE INFERRED
`Ooooo `OooO' `Oooo `Oooo `Ooooo ooooO' SPAM HOLE: FIRST AND LAST NAME JOINED WITHOUT A SPACE AT PROTONMAIL.COM
________________________________________________________________________________________________________________________________
[SPC]
IN PROGRESS ...
________________________________________________________________________________________________________________________________
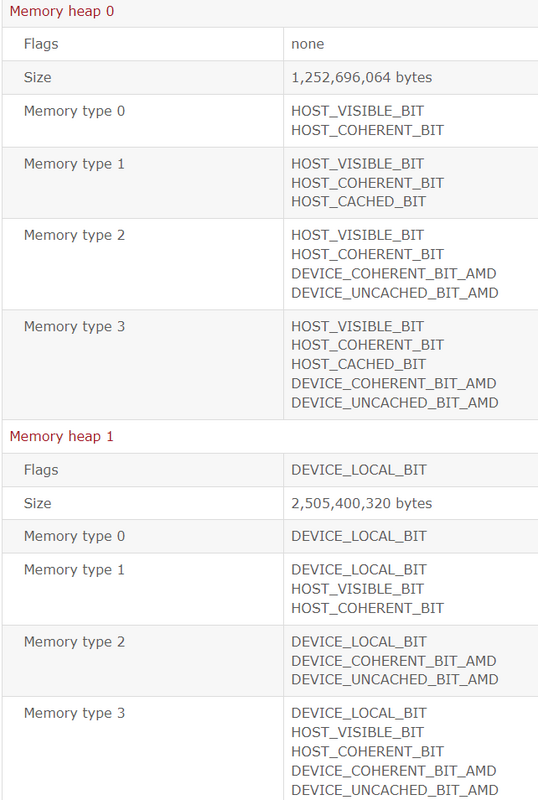
[SPC] Page Faults & BO Alloc
Post on the mechanics of CPU/GPU communication. Using AMDgpu based timing results on the SteamDeck an example,
but relating to the larger picture of PC GFX APIs like Vulkan/etc.
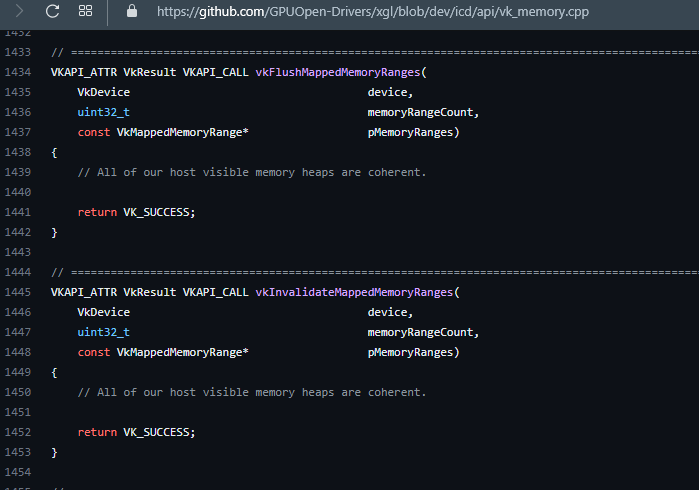
Both RADV and AMDVLK: Flush/invalidate mapped memory ranges is a NOP.
So bus-crossing dGPU traffic to HOST_VISIBLE is automatically snooping CPU caches.
The one without HOST_CACHED, is Write+Combined [WC] on store, and Uncached [UC] on read.
The one with HOST_CACHED is non-WC/UC.
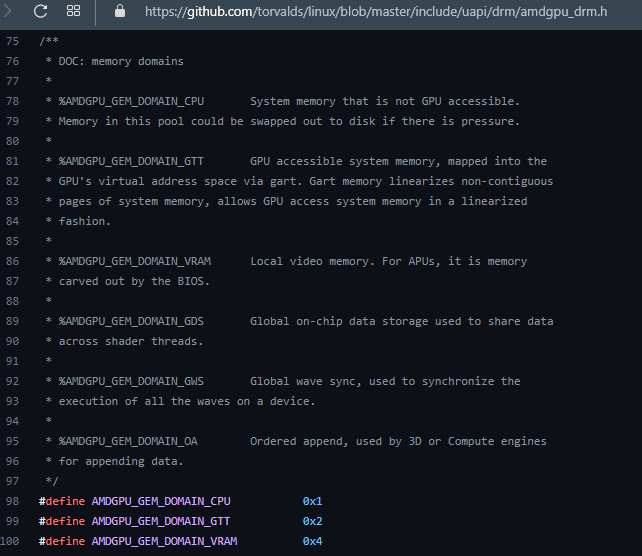
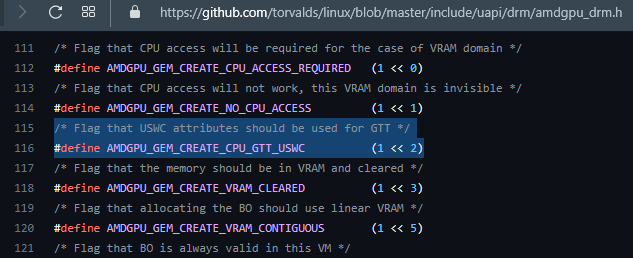
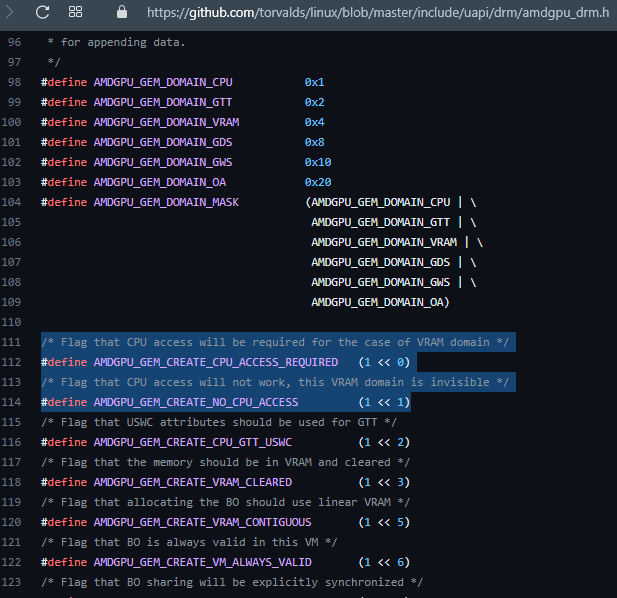
In AMDgpu (the kernel driver), likely DEVICE_LOCAL maps to AMDGPU_GEM_DOMAIN_VRAM (also the carve out on APUs)
and the non-DEVICE_LOCAL maps to AMDGPU_GEM_DOMAIN_GTT.
AMD+RADV added {DEVICE_COHERENT_BIT_AMD,
DEVICE_UNCACHED_BIT_AMD} variations to the core 4 memory types. Likely to support GPU crash debug.
But also provides a way to avoid needing to write-back (flush) GPU caches before CPU read.
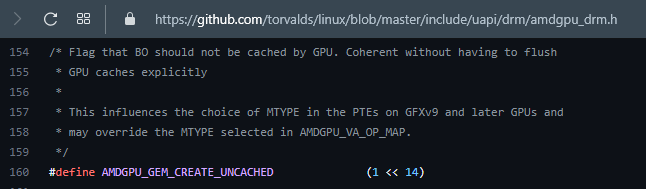
Likely AMDgpu kernel flag mapping below.
This AMDGPU_GEM_CREATE_CPU_GTT_USWC appear to toggle on WriteCombine [WC] for CPU store,
and Uncached [US] for CPU reads (cases of HOST_VISIBLE without HOST_CACHED).
For review from ChipsAndCheese
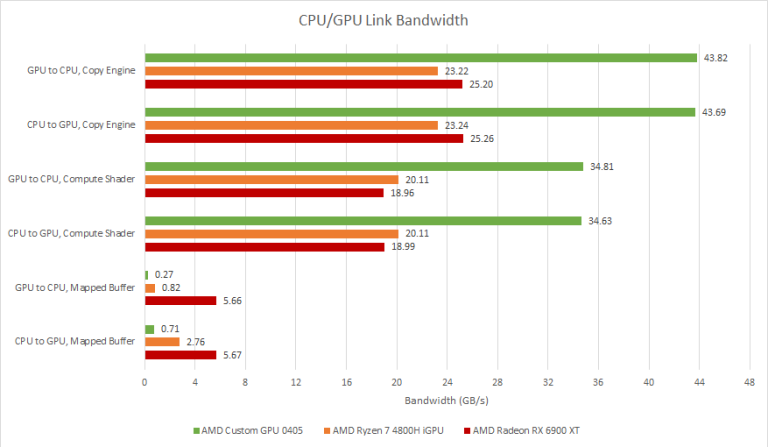
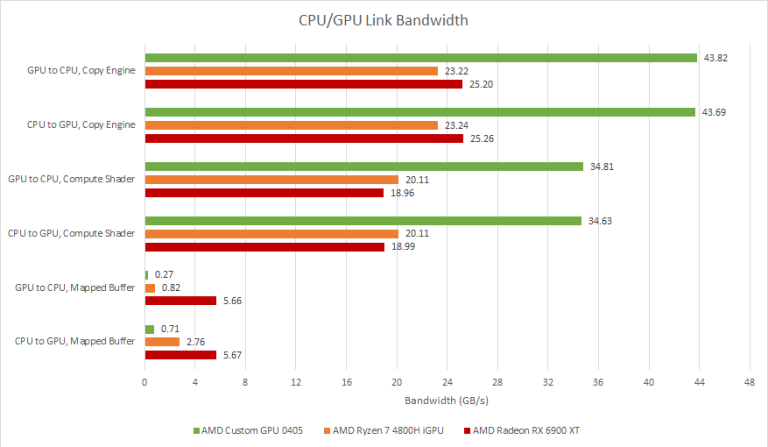
Deck bandwidths: ~71 GB/s GPU, ~43 GB/s DMA, ~34 GB/s shader copy CPU<->GPU, ~25 GB/s CPU/CPU, and damn,
brutal 0.27 GB/s CPU mapped GPU buffer reads, 0.71 GB/s CPU mapped GPU buffer writes.
And going direct to AMDgpu instead of VK on the Deck shows these kinds of bandwidths
(non-DEVICE_LOCAL, HOST_VISIBLE with HOST_CACHED and without).
So using Write-Combined is amazingly painful for stores.
Tangental Notes
- Implies that the choices one might make on dGPU PC don't necessarily port over to APUs at all. Another challenge: it takes almost 7 seconds to zero-fill using a 64-bit store for() loop the 8-GiB of mapped memory. Hints at why load times are such a challenge even in the best case.
- This all hints at why PC OS derived systems are lacking in stuffing GPU VRAM. Really need some kind of bus mastered DMA (zero-copy) between non-volatile storage (disk) and GPU DRAM to avoid this CPU-touching performance tax.
- Or for an APU, a way to have the storage device write direct to DRAM in pages setup for use on the GPU, because anything the CPU writes that the GPU reads is stuck on the strangled snooping bus or the strangled WC buffer limit on store.
- If the app tried to manage GPU memory oversubscription via these strangled CPU mappings you'd literally see many second stalls. One can only assume the kernel can do storage<->DRAM DMA for managing GPU DRAM oversubscription?
- Even if could fill VRAM in 1 sec, just 2x oversubscription of VRAM implies 1 sec delay to context switch (assuming 2 apps accessing all meM). So classic VM multitasking is useless. Only single app focus model with pinned memory makes any useful sense. Release pin on focus change.
- The trend is massive res massive VRAM paired with tiny IO bus. So the case for pinned memory and bus master transfers only grows importance as things evolve.
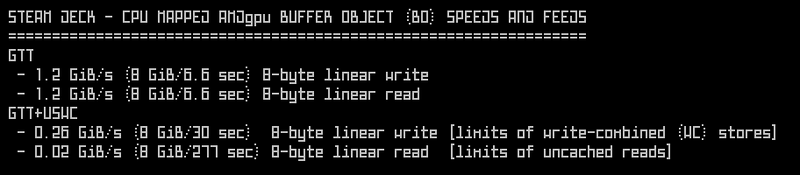
Back to SteamDeck Numbers
GTT (HOST_VISIBLE) + USWC (non-HOST_CACHED) takes 1 sec for 1st 4 GiB BO alloc, but *30 sec* for 2nd 4 GiB alloc. Kernel driver time for memory allocation (maybe page table related) can be brutal (general comment for PCs too).
Related, I think Chips&Cheese CPU/GPU link DMA and Compute Bandwidths are only measured to a GTT+USWC buffer (only supporting useless uncached CPU reads). Bandwidth exceeds the CPU's bus capacity, implies it is 'garlic' or GPU bus only accesses, direct to DRAM.
Since RADV+AMDVLK don't support user-space CPU mapped flush | invalidate,
this implies the only supported mapping to read from DRAM direct is USWC (uncached R and write+combine W).
Doing GPU stores to a CPU mapped GTT without USWC would be crippingly slow (limited by the snooping bus rate).
But this is unfortunately the only option available for CPU read back. So if doing a shader store,
it better be only a few waves and running in parallel.
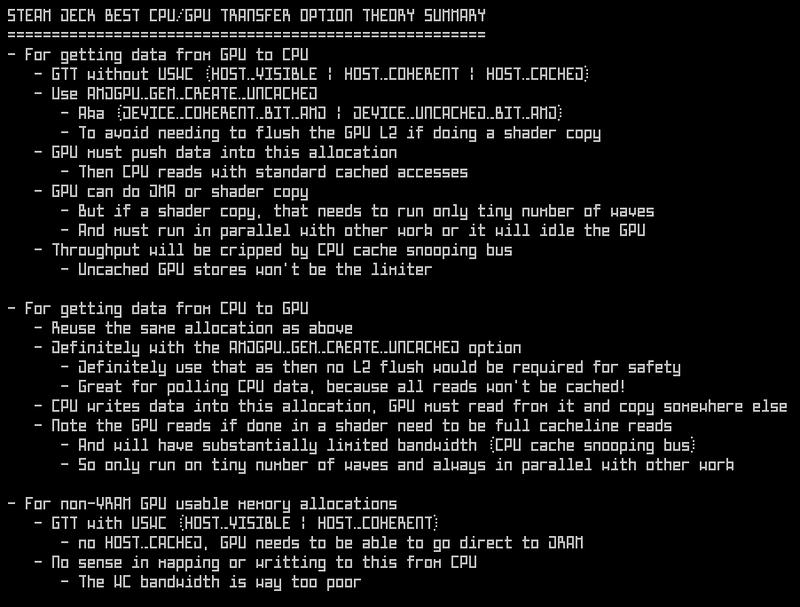
"Use GTT because it's as fast as VRAM on the Deck", could only work if GTT+USWC,
as that would be only way to get Garlic (direct to DRAM high bandwidth bus).
GTT without USWC would need Onion (slow snooping bus) because AMDgpu's only no-CPU map option is for VRAM!
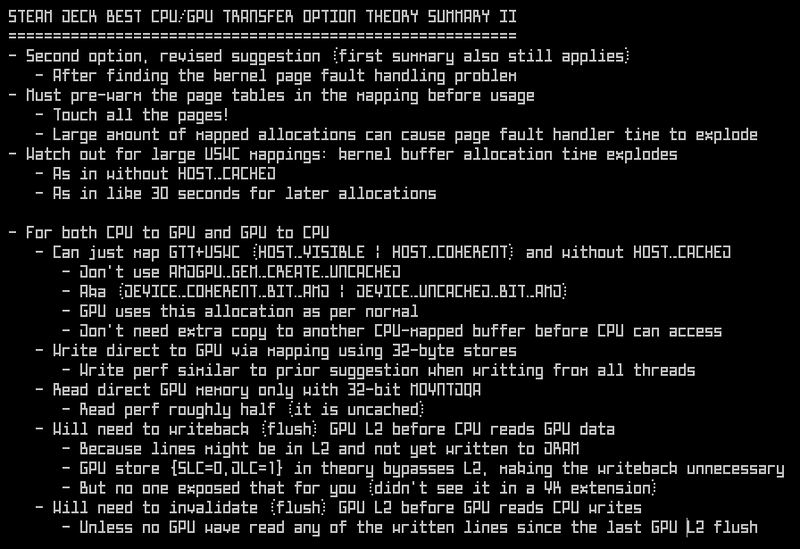
Summary of the theory on best Steam Deck practices. This is the plan for my deck-compute-only driver too.
Theory -> as in I haven't yet verified the GPU-side parts (my driver isn't that far along yet).
Possible to do better? MAYBE! CPU readback actually has 2 problems, 1st the slow GPU-side copy
(4 GiB copy via snooping bus could be almost 4 sec, but direct to DRAM via USWC might be just 160 ms).
Also CPU only has 4 MiB of L3, so the majority of 4 GiB will be uncached later.
Believe UC MTYPE (uncached) forces the CPU into serialized behavior.
My test was single thread 8-byte/access reads.
VMOVDQA_M256_YMM!
Looks like Zen2 might be able to get 32-byte/access via VMOVDQA,
and going multi-threaded (8 thread), that might be a 32x speed up.
If so might be able to approach under a GB/s for the CPU-side part (UC multithread via VMOVDQA),
which would be close enough to the non-USWC running single threaded using the cache.
What you'd really want here as a band-aid workaround is ability for the GPU to act as if the CPU map was USWC
(so go direct to DRAM), but have the CPU map act as non-USWC, so it goes through the cache.
Then some kind of hack to flush the tiny 4 MiB L3 and lower caches on the CPU.
CPU readback (reading and summing 8-byte) GTT without USWC.
- 1.16 GiB/s 1 thread
- 1.42 GiB/s 4 threads
- 1.48 GiB/s 8 threads
Going multi-core on cached readback doesn't really help much.
Proper test, parked threads waiting on futex, signal, last-1st active core timing.
Now CPU readback GTT+USWC.
- 0.13 GiB/s 4 threads 8-byte reads
- 0.24 GiB/s 8 threads 8-byte reads
- 1.15 GiB/s 8 threads 32-byte MOVNTDQA
So measurements match theory, going multi-core with MOVNTDQA uncached read
on GTT+USWC can be made to match 1 thread GTT (without USWC).
Both those results above had been using a pair of 4 GiB allocations.
The GTT+USWC one used one 4 GiB GTT+USWC for timing, and one 4 GiB GTT (unused).
And that test suffered from a 30 sec GTT BO allocation. So something was going very wrong in the page mapping.
When I rerun same test with just one 4 GiB GTT+USWC allocation, the 30 sec stall is gone, and the performance also changes.
- 18.34 GiB/s - 8 threads x 32-byte MOVNTDQA (UC)
Oh!
Perhaps there is some resource limit that kills perf if too much memory gets mapped, page faults?
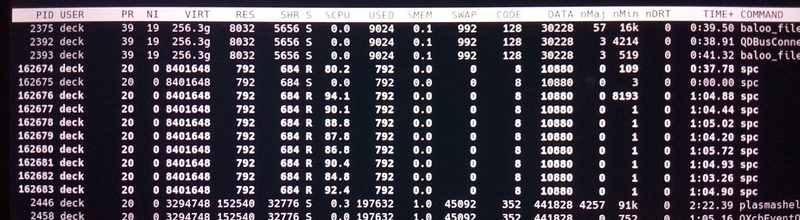
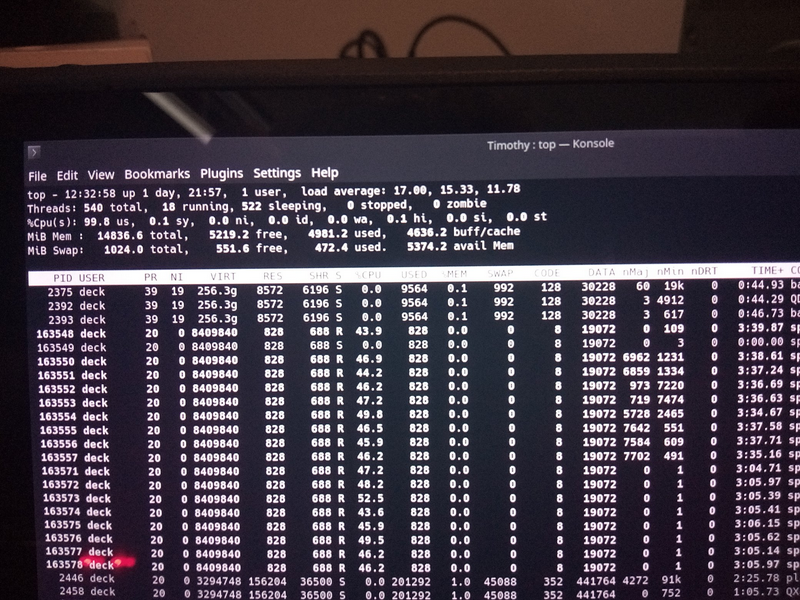
Top with thread cumulative results doesn't show anything significantly different
between the 4 GiB and 8 GiB runs in terms of page faults ... suggests it must be something else.
And yet there is obviously a bug in my multi-core tests, you can tell directly from the page fault numbers,
only one thread is taking all the faults. So it is back to finding my coding error (fail).
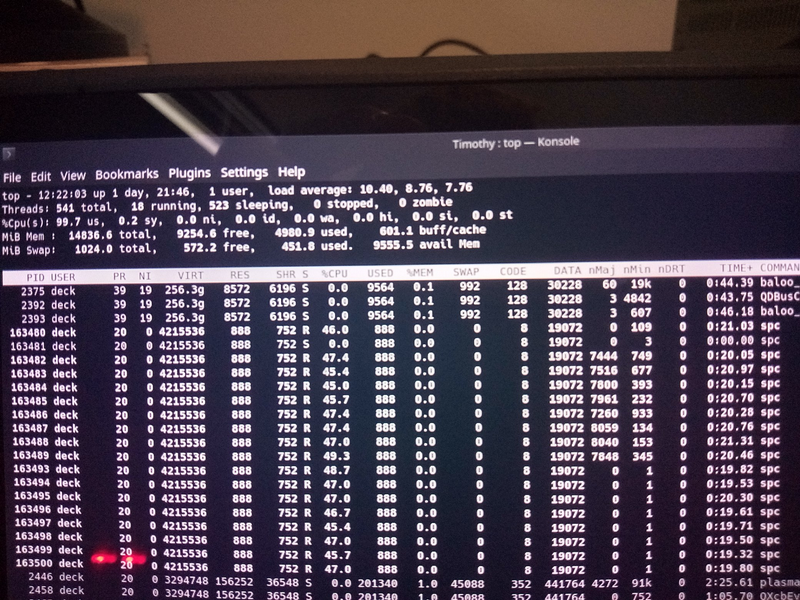
Lunch break and fixed the bug. Two runs now and leaving threads open to get TOP results.
First run definitely soaks up the page faults, second run is page fault free (expected). Both around only 7 GB/s.
And the 8 GiB of BO mapped, but only 4 GiB used run. The first pass gets only 1 GiB/s and the second gets 7 GiB/s.
Page fault number is similar to last run, can only conclude page fault costs exploded?
30 sec BO alloc time + super low bandwidth on 1st pass only (where page faults happen)
suggest that Linux Kernel logic explodes in cost if too many pages are used in this way.
~8K faults for 512 MiB accessed / thread = 64 KiB/fault ... X86-64 has either 4 KiB or 2 MiB for page size.
So not using large pages (fail).
Probably mapping 16 pages per fault.
Not sure if this implies anything about GPU page size (but certainly hoping it isn't 4 KiB, ouch).
Some other very rough measured numbers of GTT+USWC with 8 cores splitting 4 GiB of BO.
- ~7 GiB/s R
- ~10 GiB/s W then R
- ~15 GiB/s W
I think these seem plausable now (so maybe no more code bugs).
One takeaways of all this, is that you need to pre-warm the page tables for large mapped buffers
(by touching all pages) when the user isn't waiting on results.
And if you are doing batch jobs that {open device, send data to GPU, get data back, close device} you are screwed!
And lastly (maybe) comparison of GTT and GTT+USWC both 8 threads splitting streaming through 4 GiB of mapping (second pass, no page fault issues):
- R> ~14 GiB/s (GTT) and ~7 GiB/s (GTT+USWC)
- W+R> ~14 GiB/s (GTT) and ~10 GiB/s (GTT+USWC)
- W> ~13 GiB/s (GTT) and ~15 GiB/s (GTT+USWC)
So an alternative option summary for those who don't want the extra GPU-side GPU to CPU mapped buffer copy step.
If anyone is looking to repro the 30 sec stall: amdgpu_bo_alloc() one 4 GiB GTT+USWC, then one 4 GiB GTT buffer,
the second alloc causes the Deck to become unresponsive for 30 seconds.
Note, madvise() with MADV_HUGEPAGE on mapped 4 GiB region doesn't do anything (still faults at 64 KiB granularity),
and none of these MADV_{WILLNEED|POPULATE_READ|POPULATE_WRITE} have any effect either
(still waits until use before faulting, causing low initial effective bandwidth).
64KiB strided write through 4 GiB GTT+USWC (to pre-fault) costs the same as writing full 4 GiB, roughly 3 seconds.
So it is quite literally massive page fault overhead for 1st access.
No possible workaround found at this time for initial load time problems.
If doing two 4 GiB GTT+USWC allocations, there is also a 30 second BO allocate cost on the 2nd one.
And this makes the initial page fault cost for access to the first 4 GiB take another 30 seconds.
Effectively hangs the machine for a full minute.
Doing two 4 GiB GTT allocations (without USWC), doesn't incure any of the 30 second stalls.
So that problem is specific to big USWC allocations.
However the initial access page fault problem (extra 3 seconds) is there,
so a 2ndary problem with just mapping lots of APU memory.
Allocation of one 4 GiB GTT first then a 4 GiB GTT+USWC doesn't see the 30 second allocation stall.
Almost like anything post a big USWC alloc is poisioned.
And after mapping both, then accessing the GTT only, the 30 second time for page faulting comes back.
Even if you don't map the 2nd GTT+USWC, the 30 second initial page faulting time is still there,
so the act of mapping doesn't matter, simply doing the BO allocation had already doomed the Linux page management.
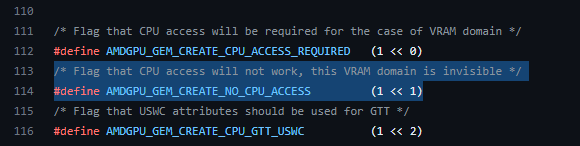
Despite header docs which imply flag only works on DOMAIN_VRAM,
using DOMAIN_GTT+AMDGPU_GEM_CREATE_NO_CPU_ACCESS is apparently what you want for non-mapped GTT allocations.
Mapped 4 GiB GTT with 4 GiB GTT+NO_CPU, drops the initial page fault time from 30 seconds to 3 sec.
________________________________________________________________________________________________________________________________
[SPC] Blame Onat
 Workspace
Workspace
One day a friend Onat said to me that on Linux Steam Deck the Vulkan driver is in user space,
and it is possible to even have both RADV and the AMD Vulkan drivers running on the system at the same time ...
And That Was Enough to Seed the Idea
An idea that could not be ignored, a platform still exists,
where in theory one could ship a game with their own generated shader binary and no driver.
A way out of GPU API Hell!
This was the day I stopped my other Windows PC projects,
and became an exclusive Steam Deck developer.
________________________________
[EAT] Life of a Steak
Sometimes old technology is the best. Like when making Steaks. Salt, short dry age, season, WOOD FIRE, eat.
________________________________
[X68]
This was an idea for a simplified machine-level x86-64 interface ...
- Subset of x86-64 where instructions are always a multiple of 32-bits
- Using ignored segment override prefixes for padding
- Instructions mapped to a human readable 8-character string
Resources
Register Naming
Characters {0-9} and {A-F} reserved for hex numbers. So the 16 registers are mapped {G-V}.
_G_ _H_ _I_ _J_ _K_ _L_ _M_ _N_ _O_ _P_ _Q_ _R_ _S_ _T_ _U_ _V_
rax rcx rdx rbx rsp rbp rsi rdi r8_ r9_ r10 r11 r12 r13 r14 r15
Addressing Mode Syntax
- @u ...... [reg(u)]
- @u23 .... [reg(u)+0x23]
- @# ...... [rip+0x########], where # is the second DWORD
- @u# ..... [reg(u)+0x########]
- @uv ..... [reg(v)+reg(u)*1]
- @2uv .... [reg(v)+reg(u)*2]
- @4uv .... [reg(v)+reg(u)*4]
- @8uv .... [reg(v)+reg(u)*8]
- @4u23 ... [reg(u)*4+0x23]
- @4u# .... [reg(u)*4+0x########]
Sizing
- 'v=@u ... reg(v) = BYTE PTR [reg(u)]
- "v=@u ... reg(v) = WORD PTR [reg(u)]
- v=@u .... reg(v) = DWORD PTR [reg(u)]
- :v=@u ... reg(v) = QWORD PTR [reg(u)]
- 'v`@u ... reg(v) = sign extend BYTE PTR [reg(u)]
Maths
- v+u ... ADD (v+=u)
- v*u ... IMUL
- ~v .... NEG
- v?u ... CMP
- -v .... NEG
- v&u ... AND
- v^u ... XOR
- v=u ... MOV
- v$u ... LEA
Examples
- u+v ...... 3E4501FE ds add r14d,r15d
- u+23 ..... 4183C623 add r14d,0x23
- u+# ...... 3E4181C6 ds add r14d,0x######## ... 32-bit immediate # is next DWORD
- u*v ...... 450FAFF7 imul r14d,r15d
- ; ........ C30F1F00 ret; nop DWORD PTR [rax]
- @u=v ..... 3E45893E mov DWORD PTR ds:[r14],r15d
- @u12=v ... 45897E12 mov DWORD PTR [r14+0x12],r15d
- :u+v ..... 3E4D01FE ds add r14,r15
- :u*v ..... 4D0FAFF7 imul r14,r15
________________________________________________________________________________________________________________________________
The 'Right' Font
- Only right angles, no aliasing even if scaled nearest
- X68.fon ... 5x10 character cell at 320x240 provides a 64x24 character cell screen
- X68D.fon ... Doubled size version (useful when not running on CRT)
- Made with Fony
 X68 at 1:2x2
X68 at 1:2x2
 X68 at 1:1
X68 at 1:1
An alternative for even smaller text? (Outtake)
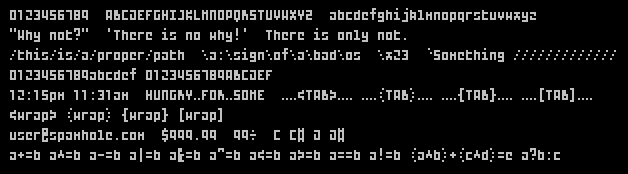 At 1:2x2
At 1:2x2
 At 1:1
At 1:1
________________________________________________________________________________________________________________________________
Windows/Linux ABIs
For reference...
Reviewing stack operations on x86-64.
Stack grows down, RSP points to last written entry.
- CALL rax ... rsp-=8; [rsp]=next(rip); rip=rax;
- POP rax .... rax=[rsp]; rsp+=8;
- PUSH rax ... rsp-=8; [rsp]=rax;
- RET ........ rip=[rsp]; rsp-=8;
Reviewing Windows and Linux ABI register conventions.
N X86 X68 WIN LXN
= === === === ===
0 rax g r r (return value)
1 rcx h a0 a3
2 rdx i a1 a2
3 rbx j sav sav
4 rsp k sav sav (stack pointer)
5 rbp l sav sav
6 rsi m sav a1
7 rdi n sav a0
8 r8 o a2 a4
9 r9 p a3 a5
a r10 q vol vol
b r11 r vol vol
c r12 s sav sav
d r13 t sav sav
e r14 u sav sav
f r15 v sav sav
Then the Windows stack conventions.
Anything less than RSP can be overwritten any time,
thus must move RSP before writing below a set RSP point.
Before a CALL, RSP must be 16-byte aligned.
There is a 32-byte 'shadow' region reserved for called function usage.
...
[RSP+0x28] A5
[RSP+0x20] A4
[RSP+0x18] not A3 (R9 shadow)
[RSP+0x10] not A2 (R8 shadow)
[RSP+0x08] not A1 (RDX shadow)
[RSP+0x00] not A0 (RCX shadow) ... 16-byte aligned
(return_goes_here)
Linux conventions.
...
[RSP+0x08] A7
[RSP+0x00] A6
(return_goes_here)
________________________________________________________________________________________________________________________________
Windows Terminal Remap
Docs for taking Windows terminal codes and mapping them into simple 8-bit single byte codes (for a portable editor).
//_______________________________________________/WINDOWS:KEYDOC
// _/KEYS\_____
// EN end
// ES escape
// BS backspace
// DN down
// DL delete
// HM home
// IN insert
// LF left
// PD page down
// PU page up
// RN return
// RT right
// SP space
// TB tab
// UP up
// _/EXCEPTIONS\___________________________________
// CTRL+h aliases CTRL+BACKSPACE
// CTRL+i aliases TAB
// CTRL+j aliases CTRL+RETURN
// CTRL+m aliases RETURN
// CTRL+[ aliases ESCAPE aliases control code start
// NO SHIFT+{BACKSPACE,RETURN,SPACE}
// NO CTRL+{`-=;',.z,TAB,SPACE}
// NO ALT+{TAB,RETURN}
// _/INPUT\_________________________
// =-=============-==-==-==-==-==-==
// A space........ 1b 20
// A ' ........... 1b 27
// A , ........... 1b 2c
// A - ........... 1b 2d
// A . ........... 1b 2e
// A / ........... 1b 2f
// A = ........... 1b 3d
// A 0 ........... 1b 30
// . . ........... .. ..
// A 9 ........... 1b 39
// A ; ........... 1b 3b
// A [ ........... 1b 5b
// A \ ........... 1b 5c
// A ] ........... 1b 5d
// A ` ........... 1b 60
// A a ........... 1b 61
// . . ........... .. ..
// A z ........... 1b 7a
// A backspace ... 1b 7f
// =-=============-==-==-==-==-==-==
// S tab ......... 1b 5b 5a
// =-=============-==-==-==-==-==-==
// insert ...... 1b 5b 32 7e
// delete ...... 1b 5b 33 7e
// page up ..... 1b 5b 35 7e
// page down ... 1b 5b 36 7e
// up .......... 1b 5b 41
// down ........ 1b 5b 42
// right ....... 1b 5b 43
// left ........ 1b 5b 44
// end ......... 1b 5b 46
// home ........ 1b 5b 48
// =-=============-==-==-==-==-==-==
// S insert ...... 1b 5b 32 36 32 7e
// S delete ...... 1b 5b 33 36 32 7e
// S page up ..... 1b 5b 35 36 32 7e
// S page down ... 1b 5b 36 36 32 7e
// S up .......... 1b 5b 31 3b 32 41
// S down ........ 1b 5b 31 3b 32 42
// S right ....... 1b 5b 31 3b 32 43
// S left ........ 1b 5b 31 3b 32 44
// S end ......... 1b 5b 31 3b 32 46
// S home ........ 1b 5b 31 3b 32 48
// =-=============-==-==-==-==-==-==
// C insert ...... 1b 5b 32 36 35 7e
// C delete ...... 1b 5b 33 36 35 7e
// C page up ..... 1b 5b 35 36 35 7e
// C page down ... 1b 5b 36 36 35 7e
// C up .......... 1b 5b 31 3b 35 41
// C down ........ 1b 5b 31 3b 35 42
// C right ....... 1b 5b 31 3b 35 43
// C left ........ 1b 5b 31 3b 35 44
// C end ......... 1b 5b 31 3b 35 46
// C home ........ 1b 5b 31 3b 35 48
// =-=============-==-==-==-==-==-==
// _/OUTPUT_MATCHING\_________ _/OUTPUT_CUSTOM\___________
// ==-==- ==-==- ==-==- ==-==- ==-==- ==-==- ==-==- ==-==-
// 00 20 SP 40 @ 60 ` 80 a0 SPa c0 e0 ` a
// 01 a c 21 ! 41 A 61 a 81 a1 INa c1 INc e1 a a
// 02 b c 22 " 42 B 62 b 82 a2 DLa c2 DLc e2 b a
// 03 c c 23 # 43 C 63 c 83 a3 PUa c3 PUc e3 c a
// 04 d c 24 $ 44 D 64 d 84 a4 PDa c4 PDc e4 d a
// 05 e c 25 % 45 E 65 e 85 a5 UPa c5 UPc e5 e a
// 06 f c 26 & 46 F 66 f 86 a6 DNa c6 DNc e6 f a
// 07 g c 27 ' 47 G 67 g 87 a7 RTa c7 RTc e7 g a
// 08 h c 28 ( 48 H 68 h 88 a8 LFa c8 LFc e8 h a
// 09 TB 29 ) 49 I 69 i 89 TBs a9 ENa c9 ENc e9 i a
// 0a j c 2a * 4a J 6a j 8a aa HMa ca HMc ea j a
// 0b k c 2b + 4b K 6b k 8b ab cb eb k a
// 0c l c 2c , 4c L 6c l 8c ac , a cc ec l a
// 0d RN 2d - 4d M 6d m 8d ad - a cd ed m a
// 0e n c 2e . 4e N 6e n 8e ae . a ce ee n a
// 0f o c 2f / 4f O 6f o 8f af / a cf ef o a
// 10 p c 30 0 50 P 70 p 90 b0 0 a d0 f0 p a
// 11 q c 31 1 51 Q 71 q 91 INs b1 1 a d1 IN f1 q a
// 12 r c 32 2 52 R 72 r 92 DLs b2 2 a d2 DL f2 r a
// 13 s c 33 3 53 S 73 s 93 PUs b3 3 a d3 PU f3 s a
// 14 t c 34 4 54 T 74 t 94 PDs b4 4 a d4 PD f4 t a
// 15 u c 35 5 55 U 75 u 95 UPs b5 5 a d5 UP f5 u a
// 16 v c 36 6 56 V 76 v 96 DNs b6 6 a d6 DN f6 v a
// 17 w c 37 7 57 W 77 w 97 RTs b7 7 a d7 RT f7 w a
// 18 x c 38 8 58 X 78 x 98 LFs b8 8 a d8 LF f8 x a
// 19 y c 39 9 59 Y 79 y 99 ENs b9 9 a d9 EN f9 y a
// 1a z c 3a : 5a Z 7a z 9a HMs ba da HM fa z a
// 1b ES 3b ; 5b [ 7b { 9b bb ; a db [ a fb
// 1c \ c 3c < 5c \ 7c | 9c bc dc \ a fc
// 1d ] c 3d = 5d ] 7d } 9d bd = a dd ] a fd
// 1e 3e > 5e ^ 7e ~ 9e be de fe
// 1f / c 3f ? 5f _ 7f BS 9f bf df ff BSa
// ==-==- ==-==- ==-==- ==-==- ==-==- ==-==- ==-==- ==-==-
// _/ENCODING_6_CHARS_INTO_32BIT\_________________________________
// char 0 - 7-bit
// char 1 - 7-bit
// char 2 - 0,31-5a -> 30-5a -> 0-2a -> 0-39 -> 6-bit
// char 3 - 0,36,3b,7e
// 0000000
// 0110110 ... extract 2 bits
// 0111011
// 1111110
// ab
// char 4 - 0,32,35
// 000000
// 110010 ... extract 2 bits
// 110101
// ab
// char 5 - 0,41,,7e - can just use 7-bit
// ---------------------------------------------------------------
// 11111111111111110000000000000000
// fedcba9876543210fedcba9876543210
// ================================
// .0000000........................ char 0 [lower 7-bits]
// ........1111111................. char 1 [lower 7-bits]
// ...............222222........... char 2 [clamp(c-0x30,0,0x39)]
// .....................33......... char 3 [(c>>2)&3]
// .......................44....... char 4 [(c>>1)&3]
// .........................5555555 char 5 [lower 7-bits]
________________________________________________________________________________________________________________________________
SPIR-V Notes
Aim
The point of this was to look at the possibility to replace GLSL with some simplified virtual assembly language
(something that is closer to 1:1 mapping to GCN ISA), and see if that can be expressed in SPIR-V.
I believe the answer to that is YES.
Notice that multi-component values like uvec4 get reduced to OpLoad and OpStore
without using OpPhi given a branch,
so a compiler would need to be able to handle optimizing with loads and stores.
Which implies it would be easy to just pre-allocate N*4 registers as N multi-component values,
then use load/store to access.
Tangentally, it is possible just in the examples below to see how SPIR-V is a great example of bad engineering
as SPIR-V obfuscates the meaning of code with very poor information density.
SPIR-V Reference
SPIR-V 1.0 Spec
Minimal SPIR-V File?
__GLSL__
#version 450
layout(local_size_x=64)in;
void main(){}
__SPIR-V__
; SPIR-V
; Version: 1.0
; Generator: Khronos Glslang Reference Front End; 7
; Bound: 11
; Schema: 0
OpCapability Shader
%1 = OpExtInstImport "GLSL.std.450"
OpMemoryModel Logical GLSL450
OpEntryPoint GLCompute %main "main"
OpExecutionMode %main LocalSize 64 1 1
OpSource GLSL 450
OpName %main "main"
OpDecorate %gl_WorkGroupSize BuiltIn WorkgroupSize
%void = OpTypeVoid
%3 = OpTypeFunction %void
%uint = OpTypeInt 32 0
%v3uint = OpTypeVector %uint 3
%uint_64 = OpConstant %uint 64
%uint_1 = OpConstant %uint 1
%gl_WorkGroupSize = OpConstantComposite %v3uint %uint_64 %uint_1 %uint_1
%main = OpFunction %void None %3
%5 = OpLabel
OpReturn
OpFunctionEnd
Adding Buffer Binding
__GLSL__
#version 450
layout(set=0,binding=1,std430)buffer b0_{uvec4 b0[4096];};
layout(local_size_x=64)in;
void main(){}
__SPIR-V__
; SPIR-V
; Version: 1.0
; Generator: Khronos Glslang Reference Front End; 7
; Bound: 17
; Schema: 0
OpCapability Shader
%1 = OpExtInstImport "GLSL.std.450"
OpMemoryModel Logical GLSL450
OpEntryPoint GLCompute %main "main"
OpExecutionMode %main LocalSize 64 1 1
OpSource GLSL 450
OpName %main "main"
OpName %b0_ "b0_"
OpMemberName %b0_ 0 "b0"
OpName %_ ""
OpDecorate %_arr_v4uint_uint_4096 ArrayStride 16
OpMemberDecorate %b0_ 0 Offset 0
OpDecorate %b0_ BufferBlock
OpDecorate %_ DescriptorSet 0
OpDecorate %_ Binding 1
OpDecorate %gl_WorkGroupSize BuiltIn WorkgroupSize
%void = OpTypeVoid
%3 = OpTypeFunction %void
%uint = OpTypeInt 32 0
%v4uint = OpTypeVector %uint 4
%uint_4096 = OpConstant %uint 4096
%_arr_v4uint_uint_4096 = OpTypeArray %v4uint %uint_4096
%b0_ = OpTypeStruct %_arr_v4uint_uint_4096
%_ptr_Uniform_b0_ = OpTypePointer Uniform %b0_
%_ = OpVariable %_ptr_Uniform_b0_ Uniform
%v3uint = OpTypeVector %uint 3
%uint_64 = OpConstant %uint 64
%uint_1 = OpConstant %uint 1
%gl_WorkGroupSize = OpConstantComposite %v3uint %uint_64 %uint_1 %uint_1
%main = OpFunction %void None %3
%5 = OpLabel
OpReturn
OpFunctionEnd
Buffer Load, Component Modify, Buffer Store
__GLSL__
#version 450
layout(set=0,binding=1,std430)buffer b0_{uvec4 b0[4096];};
layout(local_size_x=64)in;
void main(){uvec4 u=b0[0];u.x+=1u;b0[0]=u;}
__SPIR-V__
; SPIR-V
; Version: 1.0
; Generator: Khronos Glslang Reference Front End; 7
; Bound: 32
; Schema: 0
OpCapability Shader
%1 = OpExtInstImport "GLSL.std.450"
OpMemoryModel Logical GLSL450
OpEntryPoint GLCompute %main "main"
OpExecutionMode %main LocalSize 64 1 1
OpSource GLSL 450
OpName %main "main"
OpName %u "u"
OpName %b0_ "b0_"
OpMemberName %b0_ 0 "b0"
OpName %_ ""
OpDecorate %_arr_v4uint_uint_4096 ArrayStride 16
OpMemberDecorate %b0_ 0 Offset 0
OpDecorate %b0_ BufferBlock
OpDecorate %_ DescriptorSet 0
OpDecorate %_ Binding 1
OpDecorate %gl_WorkGroupSize BuiltIn WorkgroupSize
%void = OpTypeVoid
%3 = OpTypeFunction %void
%uint = OpTypeInt 32 0
%v4uint = OpTypeVector %uint 4
%_ptr_Function_v4uint = OpTypePointer Function %v4uint
%uint_4096 = OpConstant %uint 4096
%_arr_v4uint_uint_4096 = OpTypeArray %v4uint %uint_4096
%b0_ = OpTypeStruct %_arr_v4uint_uint_4096
%_ptr_Uniform_b0_ = OpTypePointer Uniform %b0_
%_ = OpVariable %_ptr_Uniform_b0_ Uniform
%int = OpTypeInt 32 1
%int_0 = OpConstant %int 0
%_ptr_Uniform_v4uint = OpTypePointer Uniform %v4uint
%uint_1 = OpConstant %uint 1
%uint_0 = OpConstant %uint 0
%_ptr_Function_uint = OpTypePointer Function %uint
%v3uint = OpTypeVector %uint 3
%uint_64 = OpConstant %uint 64
%gl_WorkGroupSize = OpConstantComposite %v3uint %uint_64 %uint_1 %uint_1
%main = OpFunction %void None %3
%5 = OpLabel
%u = OpVariable %_ptr_Function_v4uint Function
%18 = OpAccessChain %_ptr_Uniform_v4uint %_ %int_0 %int_0
%19 = OpLoad %v4uint %18
OpStore %u %19
%23 = OpAccessChain %_ptr_Function_uint %u %uint_0
%24 = OpLoad %uint %23
%25 = OpIAdd %uint %24 %uint_1
%26 = OpAccessChain %_ptr_Function_uint %u %uint_0
OpStore %26 %25
%27 = OpLoad %v4uint %u
%28 = OpAccessChain %_ptr_Uniform_v4uint %_ %int_0 %int_0
OpStore %28 %27
OpReturn
OpFunctionEnd
Now With Simple Conditional
__GLSL__
#version 450
layout(set=0,binding=1,std430)buffer b0_{uvec4 b0[4096];};
layout(local_size_x=64)in;
void main(){uvec4 u=b0[0];if(u.x!=0u)u.x+=1u;else u.x+=2u;b0[0]=u;}
__SPIR-V__
; SPIR-V
; Version: 1.0
; Generator: Khronos Glslang Reference Front End; 7
; Bound: 44
; Schema: 0
OpCapability Shader
%1 = OpExtInstImport "GLSL.std.450"
OpMemoryModel Logical GLSL450
OpEntryPoint GLCompute %main "main"
OpExecutionMode %main LocalSize 64 1 1
OpSource GLSL 450
OpName %main "main"
OpName %u "u"
OpName %b0_ "b0_"
OpMemberName %b0_ 0 "b0"
OpName %_ ""
OpDecorate %_arr_v4uint_uint_4096 ArrayStride 16
OpMemberDecorate %b0_ 0 Offset 0
OpDecorate %b0_ BufferBlock
OpDecorate %_ DescriptorSet 0
OpDecorate %_ Binding 1
OpDecorate %gl_WorkGroupSize BuiltIn WorkgroupSize
%void = OpTypeVoid
%3 = OpTypeFunction %void
%uint = OpTypeInt 32 0
%v4uint = OpTypeVector %uint 4
%_ptr_Function_v4uint = OpTypePointer Function %v4uint
%uint_4096 = OpConstant %uint 4096
%_arr_v4uint_uint_4096 = OpTypeArray %v4uint %uint_4096
%b0_ = OpTypeStruct %_arr_v4uint_uint_4096
%_ptr_Uniform_b0_ = OpTypePointer Uniform %b0_
%_ = OpVariable %_ptr_Uniform_b0_ Uniform
%int = OpTypeInt 32 1
%int_0 = OpConstant %int 0
%_ptr_Uniform_v4uint = OpTypePointer Uniform %v4uint
%uint_0 = OpConstant %uint 0
%_ptr_Function_uint = OpTypePointer Function %uint
%bool = OpTypeBool
%uint_1 = OpConstant %uint 1
%uint_2 = OpConstant %uint 2
%v3uint = OpTypeVector %uint 3
%uint_64 = OpConstant %uint 64
%gl_WorkGroupSize = OpConstantComposite %v3uint %uint_64 %uint_1 %uint_1
%main = OpFunction %void None %3
%5 = OpLabel
%u = OpVariable %_ptr_Function_v4uint Function
%18 = OpAccessChain %_ptr_Uniform_v4uint %_ %int_0 %int_0
%19 = OpLoad %v4uint %18
OpStore %u %19
%22 = OpAccessChain %_ptr_Function_uint %u %uint_0
%23 = OpLoad %uint %22
%25 = OpINotEqual %bool %23 %uint_0
OpSelectionMerge %27 None
OpBranchConditional %25 %26 %33
%26 = OpLabel
%29 = OpAccessChain %_ptr_Function_uint %u %uint_0
%30 = OpLoad %uint %29
%31 = OpIAdd %uint %30 %uint_1
%32 = OpAccessChain %_ptr_Function_uint %u %uint_0
OpStore %32 %31
OpBranch %27
%33 = OpLabel
%35 = OpAccessChain %_ptr_Function_uint %u %uint_0
%36 = OpLoad %uint %35
%37 = OpIAdd %uint %36 %uint_2
%38 = OpAccessChain %_ptr_Function_uint %u %uint_0
OpStore %38 %37
OpBranch %27
%27 = OpLabel
%39 = OpLoad %v4uint %u
%40 = OpAccessChain %_ptr_Uniform_v4uint %_ %int_0 %int_0
OpStore %40 %39
OpReturn
OpFunctionEnd
________________________________________________________________________________________________________________________________
Shipping Only 16-Bit
TLDR, going to require 16-bit shader support!
One man show, avoiding having both a 32-bit and 16-bit shader variation is highly desired.
Don't want to limit the tech based on decisions required to support 32-bit.
Would it be practical to develop and ship just a 16-bit version?
This is Vulkan only, no XBox (for certain), and no Playstation (lack of time).
Don't need 16-bit buffer access, and wave size is managed via spec constants, so relatively easy.
vulkan.gpuinfo.org - VkPhysicalDeviceFeatures::shaderInt16 - VK_KHR_shader_float16_int8::shaderFloat16
- AMD : GCN5 (Vega) and up. Hits Steam Deck (assuming they have 16-bit support in the software stack, RADV does apparently).
Note GCN4 (Polaris) has single rate 16-bit so that would be supported if AMD would stop disabling it in software.
- Intel : This says 16-bit support since Gen8 (at least in Linux).
Beyond Arc, not sure if Intel iGPUs will be fast enough to run this project.
Assuming Gen11 baseline maybe, and would need to also have 16-wide wave permutation to be optimal.
- NVIDIA : Turing (aka 20 series) and up. NV lacks some of the ISA support, but likely its emulated.
NVIDIA is not a performance limited target, so will take 'no perf uplift' or even a 'slight reduction in perf' to avoid authoring a 32-bit only shader variations.
Adding up the top cards (all NVIDIA) on
Steam Hardware Survey
shows at least 30% market won't support 16-bit.
But also that at least 30% of the market will support 16-bit, and that is good enough for me.
________________________________________________________________________________________________________________________________
X68 Epilogue
Keeping notes here incase I ever choose to revisit ...
The time for this project was replaced by [SBC].
The ability to write GPU binaries and command buffers was too great,
and after that there is effectively no need for any CPU logic except the ugly that is interfacing inside a modern OS.
________________________________
[PR0] Random Prototype 0
TODO, out of time perhaps more on these later...
Raw View Without Hole Filling Or Temporal Reconstruction
Majority of white dots are actually holes in the scene.
This is using stratified visibility, it doesn't necessarily find an intersection for each pixel.
With Temporal Reconstruction and Grain
This uses a spatial temporal reconstruction that also fills holes and removes noise.
________________________________________________________________________________________________________________________________
[PR0] Octahedral Framebuffer
Implemnted a 1024x512 rectangular layout octahedral framebuffer,
with a 360 degree cylindrical projection in a three stage pipeline.
The intermediate stage samples the octahedron
into a VGA-like 720x256 resolution target with a warped vertical.
This is to avoid perspective induced undersampling.
Final stage applies the CRT shader.
CRT shader has progressively thicker scanlines at top and bottom due to the vertical warpage.
Running full 16:9 but with a strong vignette.
The shadow mask is blended out towards the center of the screen to increase peak brightness
Horizontal blur is increased towards the right and left for the chromatic aberration.
Both the sampling of the octahedron and the VGA intermediate images are done with linear filtering
and a wide gaussian kernel.
Monochromatic tonemapping is applied afterwards.
Followed by linear-space colorizing of the greyscale.
The octahedron output is 32-bit packed {8-bit 1/(1+luma) in gamma 2.0, 13-bit x, 11-bit y}.
Sub-pixel position will later be used in filtering.
Shots below have linear temporal average of simple ray traced dummy scene,
enough to show first pass of post pipeline.
Have some changes to try before moving on to the next step in development.
Not planning on doing bloom, due to the wide gaussian kernel bright areas naturally have a slight bleed,
that is likely enough hint of brightness.
Not going to do DOF, following the strategy, if it cannot be done really well, don't bother.
Not doing motion blur, as there are no hard edges for the eye to get stuck on,
focusing on peak frame rate instead.
Not doing local contrast adaption or sharpening of any kind,
don't like the look of negative lobes inverting the edge.
________________________________________________________________________________________________________________________________
[PR0] GPU Program Bring Up
Not yet to the fun part, still laying down foundation.
Added a frame counter as a push constant for the single dispatch.
This will be enough to branch on to get to even and odd frame permutations.
So that double buffering works properly.
Dispatch sizing is a fixed 2K workgroups.
Which in theory at 64 VGPRs/wave target, is good for a 128 CU machine (in classic GCN arch).
Classic GCN has maxed out at a 64 CU machine.
Will have to modify this stuff later.
Bringing up helper GLSL structure, binding points, etc.
Initial testing involved writing to the front buffer a color based on the frame count push constant.
Front buffer rendering seems to "work" both when full-screen (low latency) and windowed (high latency).
Example screen shot shows {red,black} color due to window compositor reading during program writes.
Software Spin Wait -
With pipelined execution, a wait on a "barrier" would be expected to not wait.
The barrier only functions as a safe-guard in case something goes wrong.
Initial check to see if a barrier is signaled should thus involve a cached read
(because there would be an expectation of other waves later reading the same value).
Only if the initial read fails should an uncached spin wait be invoked.
Can see from the RDNA ISA Guide,
hardware support both in scalar and vector loads for GLC=0 reads which hit on the cache,
and GLC=1 reads which force a fetch from L2, and evict the line afterwards ("miss-evict").
Ideal spin wait would be the following,
// Want this logic in SALU only (no burning vector ALU cycles).
if(ramR.barrier<signal){ // (A.) SMEM GLC=0 read, only enter if not signaled.
while(ramRV.barrier<signal){}} // (B.) SMEM GLC=1 read, spin while not signaled.
The first wave would miss on the first (A.) read.
If the barrier passes, all future waves will hit and quickly pass.
If the spin (B.) is invoked, the second wave will miss on the first (A.) read,
because GLC=1 evicts the line post-read.
But the third will hit.
API ASK #0 - Ability to provide branch hints (coherent vs divergent, and expected branch outcome).
The compiler output (see below) is always the slower option.
It keeps the most uncommon path inline resulting in the most inefficient execution.
HARDWARE ASK #0 - Would be nice to have a way to force a miss on read but leave the line in the cache.
AMD DRIVER BUG #0 -
AMD driver sees "readonly" then ignores the other memory qualifiers.
This is both a correctness and optimization bug.
So there is no way to get SMEM loads with GLC=1 set.
This pushes the overhead into the VMEM and VALU paths for (B.).
If the first wave sees a non-signaled state in (A.)
then likely all waves on that cache will always invoke the slower (B.) spin loop,
because nothing will be refreshing the K$ line.
// layout(set=0,binding=2,std430)readonly buffer ssbo3_ {RamT ramRV;};
s_buffer_load_dword s0, s[12:15], null // 000000000020: F4200006 FA000000
// layout(set=0,binding=2,std430)volatile readonly buffer ssbo3_ {RamT ramRV;};
s_buffer_load_dword s0, s[12:15], null // 000000000020: F4200006 FA000000
// layout(set=0,binding=2,std430)coherent readonly buffer ssbo3_ {RamT ramV;};
s_buffer_load_dword s0, s[12:15], null // 000000000020: F4200006 FA000000
// layout(set=0,binding=2,std430)volatile buffer ssbo3_ {RamT ramRV;};
buffer_load_dword v1, v0, s[12:15], 0 dlc glc // 000000000020: E030C000 80030100
// layout(set=0,binding=2,std430)coherent buffer ssbo3_ {RamT ramRV;};
buffer_load_dword v1, v0, s[12:15], 0 dlc glc // 000000000020: E030C000 80030100
AMD DRIVER BUG #1 -
The above code with the VMEM spin workaround won't work due to this second bug.
AMD driver incorrectly hoists the VMEM GLC=1 load outside the loop, leading to incorrect behavior.
In the example below the signal state is zero (instead of less than some number).
if(ramR.barrier!=0u){ // (A.).
while(ramV.barrier!=0u){}} // (B.).
// This is (A.).
s_buffer_load_dword s0, s[12:15], null // 000000000028: F4200006 FA000000
s_waitcnt lgkmcnt(0) // 000000000030: BF8CC07F
s_cmp_eq_i32 s0, 0 // 000000000034: BF008000
s_cbranch_scc1 label_006C // 000000000038: BF85000C
// This should be in the (B.) loop.
buffer_load_dword v1, v0, s[12:15], 0 dlc glc // 00000000003C: E030C000 80030100
s_nop 0x0000 // 000000000044: BF800000
s_nop 0x0000 // 000000000048: BF800000
s_nop 0x0000 // 00000000004C: BF800000
s_nop 0x0000 // 000000000050: BF800000
s_nop 0x0000 // 000000000054: BF800000
s_nop 0x0000 // 000000000058: BF800000
s_nop 0x0000 // 00000000005C: BF800000
// This is (B.).
label_0060:
s_waitcnt vmcnt(0) // 000000000060: BF8C3F70
v_cmp_eq_i32 vcc_lo, 0, v1 // 000000000064: 7D040280
s_cbranch_vccz label_0060 // 000000000068: BF86FFFD
label_006C:
AMD DRIVER BUG #2 -
Now trying to trick the compiler into doing the right thing.
First with 'subgroupElect()', which generates the same bug as prior,
but adds another performance bug.
This should just be a simple operation to save and set EXEC to 1, then restore afterwards.
But instead the compiler acts as if it is already in divergent control flow ('ff1' is find first 1).
if(subgroupElect()){if(ramR.barrier!=0u){while(ramV.barrier!=0u){}}}
// This is the subgroupElect() code for a wave sized workgroup in known coherent execution.
v_mbcnt_lo_u32_b32 v1, -1, 0 // 000000000010: D7650001 000100C1
s_ff1_i32_b64 s0, exec // 000000000018: BE80147E
v_mbcnt_hi_u32_b32 v1, -1, v1 // 00000000001C: D7660001 000202C1
. . .
s_and_saveexec_b64 s[10:11], vcc // 000000000028: BE8A246A
AMD DRIVER BUG #3 -
Trying to work around the above performance bug (since running work for just lane 0 will be needed elsewhere).
Using 'gl_LocalInvocationID.x' paired with 'layout(local_size_x=32)' won't work either.
This example gets 'wave_size(32)' in the disassembly.
The compiler still uses VALU work instead of just masking EXEC.
if(gl_LocalInvocationID.x==0u){if(ramR.barrier!=0u){while(ramV.barrier!=0u){}}}
v_cmp_eq_i32 vcc_lo, 0, v0 // 000000000010: 7D040080
s_and_saveexec_b32 s0, vcc_lo // 000000000014: BE803C6A
s_cbranch_execz label_006C // 000000000018: BF880014
AMD DRIVER BUG #4 -
Last attempt to workaround the performance bug also fails.
The driver will always use the slow path burning VALU instruction(s)
for what should map to one 'S_AND_SAVEEXEC_B32 s[...],1' scalar instruction on Navi.
Using subgroup ops results in 'wave_size(64)' in the disassembly.
if(gl_SubgroupInvocationID==0u){if(ramR.barrier!=0u){while(ramV.barrier!=0u){}}}
v_mbcnt_lo_u32_b32 v1, -1, 0 // 000000000010: D7650001 000100C1
v_mbcnt_hi_u32_b32 v1, -1, v1 // 000000000018: D7660001 000202C1
v_cmp_gt_i32 vcc, 1, v1 // 000000000020: 7D080281
s_and_saveexec_b64 s[10:11], vcc // 000000000024: BE8A246A
AMD DRIVER BUG #5 -
There is another obvious bug in the above disassembly.
The program is using 'layout(local_size_x=32)'
and using 'gl_SubgroupInvocationID' or 'subgroupElect()' causes the compiler to switch to 'wave_size(64)' mode
with the high 32 lanes doing nothing.
This also means it is using 'V_MBCNT_HI_U32_B32' which wouldn't be needed in wave32 mode.
AMD DRIVER BUG #6 -
Using 'VK_EXT_subgroup_size_control' doesn't support forcing wave32 mode on Navi.
Takeaways?
If software prevents you from accessing it, the hardware doesn't actually exist.
All reasonable efforts to optimize on AMD are thwarted by it's software stack.
No choice but to ship with the slowest path on the hardware.
One optimization is possible however,
early in execution, going to process 'gl_LocalInvocationID' to write a waveID into an SGPR.
This way the VGPR for 'gl_LocalInvocationID' can be freed.
Later will use 'gl_SubgroupInvocationID' when required to build a lane index
(which materializes lane index from ALU instead of keeping it in a VGPR).
________________________________________________________________________________________________________________________________
[PR0] ABI Crossing
Thoughts on interfacing a custom language to library calls, didn't end up using the custom language for this project...
Stack Crossing
System ABIs use 16-byte aligned stacks.
ABI REQUIREMENTS AFTER A CALL INSTRUCTION
=========================================
[rsp+8] SYSV 7th argument, WIN first entry of 32-byte shadow space
[rsp+0] Return address, this is 16-byte aligned
[rsp-8] Free space
RSP BEFORE A CALL IS THUS NOT 16-BYTE ALIGNED
=============================================
[rsp+0] SYSV 7th argument, WIN first entry of 32-byte shadow space
This will use 8-byte aligned stacks, because they are not used for 16-byte data.
The ABI crossing call will need to start by aligning the stack, and restoring it before the return.
// Aligned case,
// [64] [rsp ] return address
// [56] [rsp-8 ] save rsp ....... skipped
// [48] [rsp-16] save rsp ....... final rsp points here
// -----------------------------------------------------
// Unaligned case,
// [56] [rsp ] return address
// [48] [rsp-8 ] save rsp ....... final rsp points here
// [40] [rsp-16] save rsp ....... unused
// -----------------------------------------------------
enter:
mov [rsp-8],rsp
mov [rsp-16],rsp
add rsp,-8
and rsp,~15
...
leave:
mov rsp,[rsp+0]
ret
ABIs
Only supporting x86-64 in 64-bit mode for this project.
Have a few points to cross between my custom non-language and the rest of the system.
C ABI different for Windows vs everyone else, and system calls on non-windows platforms.
The 'a' is an argument (numbered), the 'non' is non-volatile, 'vol' is volatile, and everything else is volatile.
The 'WIN' is the Windows ABI, the 'SYSV' is shared across unix/BSDs, the 'KRN' is the Linux kernel syscall convention.
REG X86-FAIL WIN SYSV KRN
======== ======== ====== ====== =======
r0 (rax) ........ return return num/ret --- reuse for call address or syscall number
r1 (rcx) ........ a0 ... a3 ... vol ... --- save
r2 (rdx) ........ a1 ... a2 ... a2 .... --- save
r3 (rbx) ........ non .. non .. non ...
r4 (rsp) SIB .... stack stack stack . --- save
r5 (rbp) RIP .... non .. non .. non ...
r6 (rsi) ........ non .. a1 ... a1 .... --- save on non-win
r7 (rdi) ........ non .. a0 ... a0 .... --- save on non-win
r8 ..... ........ a2 ... a4 ... a4 .... --- save
r9 ..... ........ a3 ... a5 ... a5 .... --- save
r10 .... ........ vol .. vol .. a3 .... --- save
r11 .... ........ vol .. vol .. vol ... --- save
r12 .... SIB .... non .. non .. non ...
r13 .... RIP .... non .. non .. non ...
r14 .... ........ non .. non .. non ...
r15 .... ........ non .. non .. non ...
Stacks must be 16-byte aligned, showing state of the stack after a call.
WIN STACK CONVENTION
====================
| [rsp+0x80] a16
[rsp+0x78] a15
| [rsp+0x70] a14
[rsp+0x68] a13
| [rsp+0x60] a12
[rsp+0x58] a11
| [rsp+0x50] a10
[rsp+0x48] a9
| [rsp+0x40] a8
[rsp+0x38] a7
| [rsp+0x30] a6
[rsp+0x28] a5
| [rsp+0x20] Shadow space
[rsp+0x18] Shadow space
| [rsp+0x10] Shadow space
[rsp+0x08] Shadow space
| [rsp+0x00] Return address, must be 16-byte aligned (rsp after call)
SYSV STACK CONVENTION
=====================
| [rsp+0x50] a16
[rsp+0x48] a15
| [rsp+0x40] a14
[rsp+0x38] a13
| [rsp+0x30] a12
[rsp+0x28] a11
| [rsp+0x20] a10
[rsp+0x18] a9
| [rsp+0x10] a8
[rsp+0x08] a7
| [rsp+0x00] Return address, must be 16-byte aligned (rsp after call)
Expected language crossing granularity is low,
so I'm not inclined to do anything other than make it easy to manage.
A language crossing will include a stack crossing as well,
as I'm not going to keep rsp 16-byte aligned.
This is bloody ugly, but it will work.
Will have to check if I have any language crossings using floating point.
ENGINE CONVENTION
=================
| [rsp+0xb8] r11
[rsp+0xb0] r10
| [rsp+0xa8] r9
[rsp+0xa0] r8
| [rsp+0x98] rdx
[rsp+0x90] rsi
| [rsp+0x88] rsp
[rsp+0x80] rdx (save volatile)
----------------
| [rsp+0x78] a16 (args)
[rsp+0x70] a15
| [rsp+0x68] a14
[rsp+0x60] a13
| [rsp+0x58] a12
[rsp+0x50] a11
| [rsp+0x48] a10
[rsp+0x40] a9
| [rsp+0x38] a8
[rsp+0x30] a7 (adjusted pointer sysv only)
| [rsp+0x28] a6 (register copy sysv only)
[rsp+0x20] a5 (register copy sysv only)
| [rsp+0x18] a4 (copied back to registers before the call)
[rsp+0x10] a3
| [rsp+0x08] a2
[rsp+0x00] a1
// On entry,
// - rax is the address to call
// - rcx is future stack pointer for call
entry:
mov [rcx+0x80],rdx
mov [rcx+0x88],rsp
#if SYSV
mov [rcx+0x90],rsi
mov [rcx+0x98],rdi
#endif
mov [rcx+0xa0],r8
mov [rcx+0xa8],r9
mov [rcx+0xb0],r10
mov [rcx+0xb8],r11
#if WIN
mov rsp,rcx
mov r9,[rcx+0x18]
mov r8,[rcx+0x10]
mov rdx,[rcx+0x08]
mov rcx,[rcx+0x00]
#endif
#if SYSV
lea rsp,[rcx+0x30]
mov r8,[rcx+0x20]
mov r9,[rcx+0x28]
mov rdi,[rcx+0x00]
mov rsi,[rcx+0x08]
mov rdx,[rcx+0x10]
mov rcx,[rcx+0x18]
#endif
call rax
#if WIN
mov rdx,[rsp+0x80]
mov r8,[rsp+0xa0]
mov r9,[rsp+0xa8]
mov r10,[rsp+0xb0]
mov r11,[rsp+0xb8]
mov rsp,[rsp+0x88]
#endif
#if SYSV
mov rdx,[rsp+0x80-0x30]
mov rsi,[rcx+0x90-0x30]
mov rdi,[rcx+0x98-0x30]
mov r8,[rcx+0xa0-0x30]
mov r9,[rcx+0xa8-0x30]
mov r10,[rcx+0xb0-0x30]
mov r11,[rcx+0xb8-0x30]
mov rsp,[rcx+0x88-0x30]
#endif
ret
________________________________
[GPU] Links
________________________________________________________________________________________________________________________________
[GPU] 3D Barycentric
Useful for skinning volumetric data
d=1-(a+b+c) ... coordinates must sum to one
r = point to convert into barycentric
r{a,b,c,d} = points of tetrahedron
{a,b,c} = inv(T)*(r-rd)
T =
x1-x4 x2-x4 x3-x4
y1-y4 y2-y4 y3-y4
z1-z4 z2-z4 z3-z4
INVERT A 3x3 MATRIX
=======================
a b c
d e f = A
g h i
(ei-fh) -(bi-ch) (bf-ce)
-(di-fg) (ai-cg) -(af-cd) * 1/det(A)
(dh-eg) -(ah-bg) (ae-bd)
det(A)
(ei-fh) * a -(di-fg) * b + (dh-eg) * c
________________________________________________________________________________________________________________________________
[GPU] Shader Device Clock
VK_KHR_shader_clock - device clock support
- AMD/NVIDIA : Supports device clock on all platforms that have 16-bit support
- Intel : No support for shader device clock
TODO: Is NVIDIA's device shader clock a consistent frequency?
________________________________________________________________________________________________________________________________
[GPU] Wave OPs
Suggestion of API and implementation for wave operations.
This is a copy of what I like for personal development.
=========
TERMS
=========
P1 ... 'predicate' (bool single component)
I1 ... 'integer' (32-bit signed integer single component)
UI1 .. 'unsigned integer'
W1 ... 'word' (16-bit signed integer)
C .... 'coherent' (function is static or dynamically uniform control flow)
V .... 'volatile' (function can be called in unknown control flow)
=====================================
AVOIDING PROBLEMS WITH DIVERGENCE
=====================================
Pass around 'P1 laneMask' and only go into divergent control flow locally.
This requires a different style of programming.
P1 laneMask = ...; // Existing lane mask value.
P1 laneMask2 = laneMask & newMask; // Make a local lane mask for a new subset of active threads.
if(laneMask2){ ... } // Do logic which is limited to a subset of lanes.
f(laneMask,...); // Do logic which is limited to older subset of lanes.
Note above, 'f()' gets the lane mask passed in.
So 'f()' is always called from dynamically uniform control flow.
And can thus do any operations that require all lanes active.
The standard method of possibly having dynamically divergent control flow cannot do that.
=======
API
=======
NO 'gl_SubgroupInvocationID' or 'WaveGetLaneIndex()'
- INSTEAD only launch 1D workgroups and compute from 'gl_LocalInvocationID.x' and 'SV_GroupThreadID.x'
- 2D coordiates are always generated from a 1D workgroup due to needing lane swizzling to get perf
- Shader can avoid the AND operation if workgroup is know to be wave sized
- May want to maintain a 16-bit lane index to save space in some cases
- AMD
- The 'gl_LocalInvocationID.x' is placed in 'v0' before program launch (fast path)
- Driver will NOT optimize 'gl_SubgroupInvocationID' to 'gl_LocalInvocationID.x'
- The 'gl_SubgroupInvocationID' gets built (slow path)
- Using 2 VALU instructions via V_MBCNT_{HI,LO}_U32_B32 which is possibly slower (wave64, or 1 op wave32)
NO GENERIC SHUFFLE VIA 'subgroupShuffle()' OR 'WaveReadLaneAt(,nonUniformValue)'
- This is because of min spec hardware portability
- See 'Quad' and 'WaveXor' cases for constrained shuffle usage
- AMD
- DS_SWIZZLE_B32 only works in groups of 32 lanes (on GCN and RDNA)
- Same with the introduction of DS_*PERMUTE_B32 (note AMD ISA guide has some incorrect descriptions on this)
- GCN hardware is only wave64
- No way to easily portably force wave32 on RDNA
- So no way to guarantee usage of DS_BPERMUTE_B32 (wave32 only path)
- The wave64 path ends up using a V_READLANE_B32 waterfall loop (could be 64 interations, so unusably slow)
- Forced to use LDS for this kind of functionality
- No need for new API to use LDS
NO USING 'subgroupElect()' OR 'WaveIsFirstLane()'
- Both have the overhead of needing to find the first lane in possibly divergent control flow
- They are thus slow
- Instead manually mask to lane 0 via 'if((gl_LocalInvocationID.x & waveSizeMinusOne)==0)'
- Where the AND part is skipped for wave sized workgroups
- AMD
- Driver output for 'subgroupElect()' is expensive
- It is not optimized for even compile-time known uniform control flow
NO READ-FIRST-LANE
- Because on some platforms this implies using 'find-first-one' to figure out the first active lane
- So instead only call from non-divergent control flow and use explicit lane=0 in function calls
- This will be slightly less optimal (probably not measurable) on AMD, but better overall
- AMD
- 'V_READFIRSTLANE_B32 d,s' is a 32-bit instruction
- 'V_READLANE_B32 d,s,0' is a 64-bit instruction (slightly less optimal)
WITH SOME EXCEPTIONS, NO LANE SHARING BEYOND GROUPS OF 16 LANES
- Supported on all AMD and NVIDIA hardware
- Should in theory work on Intel hardware (they can do wave16)
- Wave16 is their fast path
- Exceptions
- Single lane read/write
- Ballot
I1 Quad{0,1,2,3,X,Y,D}CI1(I1 v)
- {0,1,2,3} selects quad element
- Separate functions force compile-time uniformity (portable fast path)
- DX: QuadReadLaneAt(,{0,1,2,3})
- VK: subgroupQuadBroadcast(,{0,1,2,3})
- {X,Y,D} swap with directional neighbor
- DX: QuadReadAcross{X,Y,Diagonal}()
- VK: subgroupQuadSwap{Horizontal,Vertical,Diagonal}()
- AMD: all DPP ops (fast path)
- GL: emulation?
- Can use dFd{x,y}Fine() functions for emulation
- See 'GPU Pro 2' "Shader Amortization using Pixel Quad Message Passing"
- However {ES,WebGL} lacks the 'Fine()' functions
- ES?: might be able to use 'GL_FRAGMENT_SHADER_DERIVATIVE_HINT' 'GL_NICEST'
void WavePutCI1(inout I1 dst, I1 src, I1 dynamicallyUniformLaneDst, I1 laneSrc)
- Emulation is possible because 'C' (only callable from dynamically uniform flow control)
- This could be useful for storing stacks in a VGPR
- This is a function since it can be mapped without emulation to a hardware instruction on AMD
- The 'laneSrc' is passed in to enable fast path if wave-sized workgroups vs multi-wave workgroups
- Usage,
WavePutCI1(dst, src, 2, (gl_LocalInvocationID.x & waveSizeMinusOne))
WavePutCI1(dst, src, 2, gl_LocalInvocationID.x )
- Emulation,
if(dynamicallyUniformLaneDst == laneSrc) d = x;
- AMD: V_WRITELANE_B32
- Ignores EXEC mask
I1 WaveGetCI1(I1 src, I1 dynamicallyUniformLaneSrc)
- Return 'src' value from lane 'dynamicallyUniformLaneSrc'
- For review the 'C' is 'coherent' meaning can only be called from dynamically uniform control flow
- For review the 'I1' is 32-bit integer
- AMD: V_READLANE_B32
- Works for wave32|wave64
- Ignores EXEC mask
I1 WaveXor1CI1(I1 src)
I1 WaveXor2CI1(I1 src)
I1 WaveXor4CI1(I1 src)
I1 WaveXor8CI1(I1 src)
- Designed to support 2D reductions from 4x4:1
- Requires minimum wave16 support (Intel's fast path)
- VK: subgroupShuffleXor(src, {1,2,4,8})
- DX
- AMD
- subgroupShuffleXor(,{1,2}) uses DPP quad permute
- subgroupShuffleXor(,4) uses DPP row XOR mask
- subgroupShuffleXor(,8) uses DPP row rotate by 8
- subgroupShuffleXor(,16) uses DS_SWIZZLE_B32 (which requires S_WAITCNT, slower)
- subgroupShuffleXor(,32) uses a horrible amount of code for wave64 (unusably slow)
FOR REFERENCE, THE CORRECT WAY TO DO ATOMIC APPEND
- This gets around stupid driver behavior of AMD
- AMD pattern matches atomicAdd(,staticUniform) and turns it into garbage
- Can fix it by atomicAdd(,dynamicallyUniform) where the compiler doesn't see staticUniform
- Instead do this,
P1 p=...; // Set to true to append, false to not append
UI4 b=subgroupBallot(p);
UI1 stopStupid=gl_LocalInvocationID.x>>31; // Generate a VGPR zero that the compiler doesn't pattern match
UI1 c=subgroupBallotBitCount(b)+stopStupid; // Force the compiler to promote from SGPR to VGPR
UI1 d=0;
if(gl_LocalInvocationID.x==0)d=atomicAdd(...,c); // Do the atomic on lane zero only
UI1 e=subgroupBallotExclusiveBitCount(b); // Factor this work in the latency window of the atomic add
subgroupBarrier(); // Required to be API safe
d=subgroupBroadcast(d,0); // Fast lane zero broadcast avoids 'find-first-one' overhead
d+=e; // Output position for append
________________________________________________________________________________________________________________________________
[GPU] Float Bool Fixes
There are times when there is a need to do bool logic inside floating point numbers.
Here is a good starting point for implementing such logic,
with comments about implementation on AMD GPUs.
- 1.0 ............ true
- 0.0 ............ false
- And(x,y) ....... min(x,y)
- And(x,y) ....... saturate(x*y)
- And3(x,y,z) .... min3(x,y,z) ........ 1 op (32-bit/16-bit), 2 ops (packed 16-bit, no packed MIN3)
- AndOr(x,y,z) ... saturate(x*y+z)
- AndNot(x,y) .... -x*y+1.0
- Gt(x,y) ........ Gtz(x-y) ........... 2 ops
- Gtz(x) ......... saturate( INF*x) ... {NaN := 0, x GT 0 := 1, else 0}
- Lt(x,y) ........ Ltz(x-y) ........... 2 ops
- Ltz(x) ......... saturate(-INF*x) ... {NaN := 0, x LT 0 := 1, else 0}
- Ne(x,y) ........ Gtz(abs(x-y)) ...... 2 ops (32-bit), 3 ops (16-bit, ABS not free)
- Not(x) ......... 1.0-x
- Or(x,y) ........ max(x,y)
- Or(x,y) ........ saturate(x+y)
- Or3(x,y,z) ..... max3(x,y,z) ........ 1 op (32-bit/16-bit), 2 ops (packed 16-bit, no packedk MAX3)
- Sel(x,y,z) ..... z*y+((-z)*x+x) ..... z==0.0?x:y, 2 ops, preserves precision
The following get more expensive (extra op).
- Le(x,y) ... Not(Gt(x,y))
- Ge(x,y) ... Not(Lt(x,y))
- Eq(x,y) ... Not(Ne(x,y))
They could be faster if there was a way to run the hardware in a mode without NaNs,
with modified floating point rules.
- INF-INF := NaN ...... Actual IEEE rule (a problem)
- (+/-)INF*0 := NaN ... Actual IEEE rule (a problem)
- WOULD RATHER HAVE NO NANs AND INSTEAD THIS LOGIC
- -INF+INF := 0 ....... Desired rule
- -INF-INF := -INF .... Desired rule
- +INF+INF := +INF .... Desired rule
- SO THE FOLLOWING IS POSSIBLE
- Eq(x,y) ............. saturate(-INF*abs(x-y)+INF)
- Ge(x,y) ............. Gez(x-y)
- Gez(x) .............. saturate(+INF*x+INF)
- Le(x,y) ............. Lez(x-y)
- Lez(x) .............. saturate(-INF*x+INF)
Detailed logic using new rules.
EQ
==
saturate((-INF*{ 0.0})+INF) ... saturate(( 0.0)+INF) ... saturate(+INF) ... 1.0
saturate((-INF*{+INF})+INF) ... saturate((-INF)+INF) ... saturate( 0.0) ... 0.0
saturate((-INF*{ +})+INF) ... saturate((-INF)+INF) ... saturate( 0.0) ... 0.0
GEZ
===
saturate((+INF*{ 0.0})+INF) ... saturate(( 0.0)+INF) ... saturate(+INF) ... 1.0
saturate((+INF*{-INF})+INF) ... saturate((-INF)+INF) ... saturate( 0.0) ... 0.0
saturate((+INF*{ -})+INF) ... saturate((-INF)+INF) ... saturate( 0.0) ... 0.0
saturate((+INF*{+INF})+INF) ... saturate((+INF)+INF) ... saturate(+INF) ... 1.0
saturate((+INF*{ +})+INF) ... saturate((+INF)+INF) ... saturate(+INF) ... 1.0
LEZ
===
saturate((-INF*{ 0.0})+INF) ... saturate(( 0.0)+INF) ... saturate(+INF) ... 1.0
saturate((-INF*{-INF})+INF) ... saturate((+INF)+INF) ... saturate(+INF) ... 1.0
saturate((-INF*{ -})+INF) ... saturate((+INF)+INF) ... saturate(+INF) ... 1.0
saturate((-INF*{+INF})+INF) ... saturate((-INF)+INF) ... saturate( 0.0) ... 0.0
saturate((-INF*{ +})+INF) ... saturate((-INF)+INF) ... saturate( 0.0) ... 0.0
Case For Hardware FAMA
- Leverage all of the typical register read banking (4 way) with 4 operand instructions
- FAMA as in FUSED ADD MULTIPLY ADD, introduce a pre adder
- e = (a + b) * c + d ... fama(a,b,c,d)
- This enables single instruction lerp(a,b,c) := (b-a)*c+a assuming no precision loss
- Along with single instruction bool logic: Gtz(), Ltz(), Ne(), Sel() := lerp(), etc
- Or3(x,y,z) ... saturate(fama(x,y,1.0,z))
- etc
________________________________________________________________________________________________________________________________
[GPU] Log Depth Encoding
For reference...
// LOG DEPTH ENCODING
// ==================
// - Don't need too much precision around the minimum traversable coordinate
// - Or alternatively can clip on near plane
// - This logic improves precision by a good amount (1/118 to 1/174)
// - When s=2047, n=256, a=1/256, m=2^25
// - Encoding: x=log2(z*a+(1-a*n))*b -> {0 to s}
// - m ... maximum depth value that can be encoded
// - n ... minimum depth value that can be encoded
// - s ... maximum step value
// - z ... {0 to m}
// - a ... controls distribution close to zero
// - b ... s/log2(m*a+1-n*a)
// - Decoding: z=exp2(x*(1/b))*(1/a)+(n-(1/a))
Why not just mask part of a FP16 value and use that instead of log depth encoding?
Float Toy
// - Breakdown
// fedcba9876543210
// ================
// s............... sign (ignore)
// .eeeee.......... exponent (don't want top bit, due to wasted enocding)
// ......mmmmmmmmmm mantissa
// ----------------
// ..eeeemmmmmmm... possible encoding for simple masking
// ..11111111111... 1.993 (around 2)
// ..00000000001... 4.8e-7 (around 1/2M)
// - Using simple masking burns roughly 1/16 of encoding in a linear region
// - Complex masking can only approach 1/32 of encoding
// - This neglects lower 3-bits of precision (gets worse if including more bits)
// - So NO!
________________________________________________________________________________________________________________________________
[GPU] Ultimate Video Quality
- Very Few Dispatches Each Frame -
CPU is doing effectively nothing. All the game logic is on the GPU.
- Input Sampled on the GPU -
Background CPU thread is pushing latest input to GPU readable buffer.
GPU is reading CPU input and generating camera translational update right before view-dependent rendering.
- Camera Rotation Independent Rendering -
Scene is rendered initially into an Octahedron.
This rendering is dependent on camera translation but not camera angle.
GPU is reading CPU input again and generating camera rotation update right before final view-angle-dependent rendering,
which takes the octahedral space and generates the cylindrical projection the user sees.
- V-Sync is ON -
This is the only way to ensure consistent motion is visually consistent in time.
TERMS
=========
latency ... as in input read on GPU to start of first frame's line on CRT (ignoring H blanking)
gi ........ GPU view independent work
gd ........ GPU view translation dependent work
gc ........ GPU view camera angle dependent work
MAXED OUT GPU
==================
/_gi5_/_gd5_/_gc5_//_gi6_/_gd6_/_gc6_//_gi7_/_gd7_/_gc7_/
[____scanout_4____][____scanout_5____][____scanout_6____]
^ ^ ^
| |<---->| ... Camera rotation latency (slightly lower)
| |
|<---------->| ... Camera translation and button to flash latency (slightly higher)
MAXED OUT GPU - LATENCY INDEPENDENT OF CPU WORK
===================================================
(_cpu6_) (_cpu7_) (_cpu8_)
/_gi5_/_gd5_/_gc5_//_gi6_/_gd6_/_gc6_//_gi7_/_gd7_/_gc7_/ -+
[____scanout_4____][____scanout_5____][____scanout_6____] |
|
or |- same latency
|
(_cpu6_) (_cpu7_) (_cpu8_) |
/_gi5_/_gd5_/_gc5_//_gi6_/_gd6_/_gc6_//_gi7_/_gd7_/_gc7_/ -+
[____scanout_4____][____scanout_5____][____scanout_6____]
NON-MAXED OUT GPU - LATENCY DEPENDENT ON WHEN GPU WORK STARTS
=================================================================
/_gi5_/_gd5_/_gc5_/ /_gi6_/_gd6_/_gc6_/ /_gi7_/_gd7_/_gc7_/
[________scanout_4________][________scanout_5________][________scanout_6________]
^ ^ ^
| |<---->|
| | ... Lower latency
|<---------->|
vs
/_gi5_/_gd5_/_gc5_/ /_gi6_/_gd6_/_gc6_/ /_gi7_/_gd7_/_gc7_/
[________scanout_4________][________scanout_5________][________scanout_6________]
^ ^ ^
| |<------------>|
| | ... Higher latency
|<------------------>|
________________________________________________________________________________________________________________________________
[GPU] Unlimited Boy
Fantasy console inspired by the 160x144 pixel and 4 shades of grey Gameboy...
Unlimited Boy Concept
- Push up to 256x128 = 32768 pixels (Letterboxed NES, better for modern 16:9 displays)
- Push up to 3-bit/pixel (8 shade monochome)
- Separate sprite mask from sprite, so sprite can use all 8 shades
- Sprite uses 4 bit planes {mask, high bit, med bit, low bit}
- 8x4 bit plane in one 32-bit integer, full 8x4 sprite in a 16-byte 'uvec4' (single load)
- Get 64 million sprites in 1 GiB of buffer memory (uncompressed)
- Can fetch a sprite into K$ using one S_LOAD_DWORDX4 operation
- ----
- 64 lane workgroup = 32x1 pixels / lane = 256x8 pixel row
- 16 workgroups / screen ... not enough to fill GPU
- Each workgroup working on a subset of the "unlimited" sprite list
- Ordered composite of workgroups at end
- ----
- Workgroup works on a sprite at a time
- Each lane has 4 uints (one per bit plane) for 32x1 pixels
- Extract the associated 8x1 line from sprite for the 4 planes
- Shift and mask, then compsite with logic ops
- ----
- Can burn sprites for various things (effectively unlimited memory)
- Like have sub-pixel shift sprites (4 sprites = 2x2, or 16 sprites = 4x4)
- Or different brightness, rotation angles, scaling, etc
- ----
- Without using extra sprite memory, could introduce dither mask modifier
- Enables a sprite to have dithered 'transparency'
- Could then split sprites into N copies, each with different 'dither'
- Where all the dithers add up to the origional sprite
- So that Z ordered sprites won't have pop, because the 'sprite' is split into N layers
- So as sprites occupy similar Z they blend together
________________________________
[PRG] Links
________________________________________________________________________________________________________________________________
[PRG] Lottes6x16 Font
A Bitmap Terminal Font
Designed for monospace text editing.
Lottes6x16.fon - Easy to find for general app usage like in Notepad2.
LottesTerminal6x16.fon - Special version to make work in windows terminal.
As a programmer who sticks to 1080p displays, I use this bitmap font for source editing and windows terminal.
The font was made using Fony.
Right click on the file and "Install" to install.
Use "6x16" in the terminal.
________________________________________________________________________________________________________________________________
[PRG] Page Warming
Something From an Existing 'C' Engine ...
The desire for the user is to have a hitch-free experience.
OS design today seems more around bloatware, not designed for tiny tight binaries.
The problem being that pages are not necessarily there until needed,
and that process can be a latency chain nightmare (hitch fest).
To workaround this problem, on program launch, and repeated each time the app gets focus, a background thread walks all pages.
- Code is warmed first, with simple read of the first word of each 4K page.
- Data is warmed next, with an atomic ADD of a loaded zero of the first word of each 4K page.
The atomic forces initially zero-fill pages to be converted from the common zero-fill page to a unique dedicated page.
The 'loaded zero' (unknown at compile time) is done to make sure a smart compiler cannot factor out the atomic operation.
All code is done with ROM_ defined to 1, the source file simply includes itself, wrapped with beginning WrmBas() and ending WrmEnd() functions
so it becomes possible to easily know the range of addresses for code.
#define ROM_ 1
S_ void WrmBas(void){Crash();}
#include "nvg0.c"
S_ void WrmEnd(void){Crash();}
#undef ROM_
All data is placed into one structure (with RAM_ defined to 1, source including itself), so finding start and end is easy.
#define RAM_ 1
typedef struct{
#include "nvg0.c"
A_(64) I1 end[1024*1024/4];}RamT;S_ A_(64) L1 ramM[sizeof(RamT)/8];
#define ramR TR_(RamT,L1_(ramM))
#define ramV TV_(RamT,L1_(ramM))
#undef RAM_
________________________________________________________________________________________________________________________________
[PRG] Self Modifying Binary
Single File App
Turns out this still works in Win10. But is likely to not work in the future (for another post).
The concept is simple,
instead of having a binary and data file(s),
just have a binary,
where the application saves it's configuration state directly into the binary.
Or the step beyond, saving a RAM snapshot into the binary,
so the application can easily startup where it last left off,
and the user can have any number of save points by having different binaries.
Distribution and install of the application is just place the file wherever you want to run it from.
Uninstall is just delete the binary.
Very easy setup, no registry or config file garbage.
The technique is quite simple.
- When the binary starts it copies itself to a temp file, then launches the temp file, then exits.
- The temp file launch runs the application.
- Temp file launch is free to modify the original binary (which is no longer running).
Not shown below, but on exit, the temp file launch could launch the original binary with a command to delete the temp file.
This would work to automatically not leave a garbage file around.
Proof of Concept
//
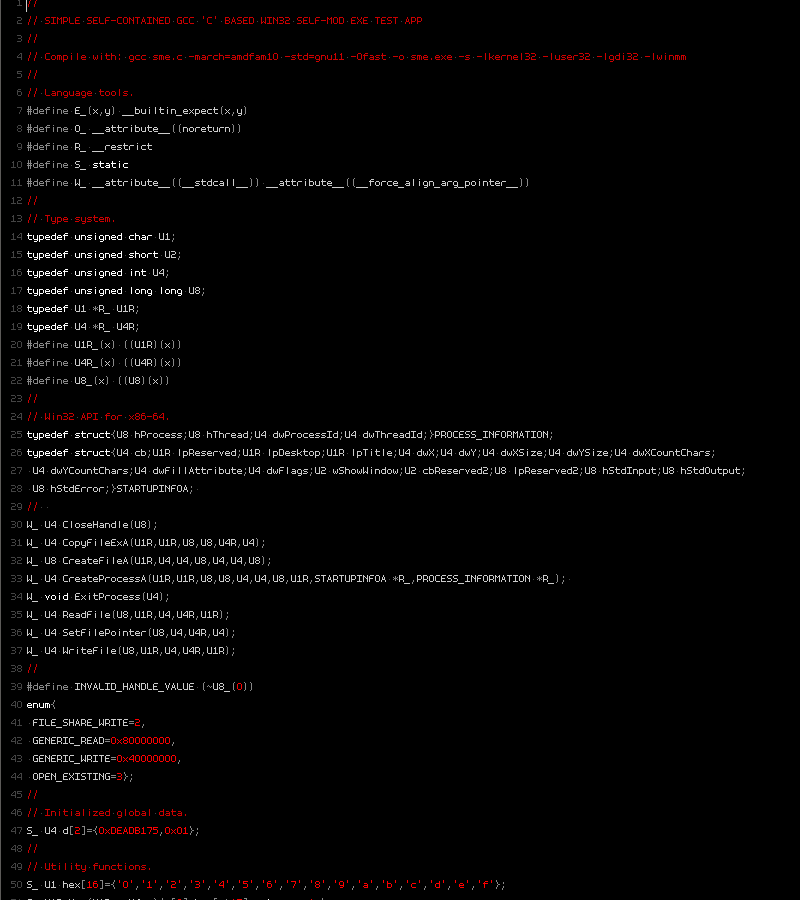
// SIMPLE SELF-CONTAINED GCC 'C' BASED WIN32 SELF-MOD EXE TEST APP
//
// Compile with: gcc sme.c -march=amdfam10 -std=gnu11 -Ofast -o sme.exe -s -lkernel32 -luser32 -lgdi32 -lwinmm
//
// Language tools.
#define E_(x,y) __builtin_expect(x,y)
#define O_ __attribute__((noreturn))
#define R_ __restrict
#define S_ static
#define W_ __attribute__((__stdcall__)) __attribute__((__force_align_arg_pointer__))
//
// Type system.
typedef unsigned char U1;
typedef unsigned short U2;
typedef unsigned int U4;
typedef unsigned long long U8;
typedef U1 *R_ U1R;
typedef U4 *R_ U4R;
#define U1R_(x) ((U1R)(x))
#define U4R_(x) ((U4R)(x))
#define U8_(x) ((U8)(x))
//
// Win32 API for x86-64.
typedef struct{U8 hProcess;U8 hThread;U4 dwProcessId;U4 dwThreadId;}PROCESS_INFORMATION;
typedef struct{U4 cb;U1R lpReserved;U1R lpDesktop;U1R lpTitle;U4 dwX;U4 dwY;U4 dwXSize;U4 dwYSize;U4 dwXCountChars;
U4 dwYCountChars;U4 dwFillAttribute;U4 dwFlags;U2 wShowWindow;U2 cbReserved2;U8 lpReserved2;U8 hStdInput;U8 hStdOutput;
U8 hStdError;}STARTUPINFOA;
//
W_ U4 CloseHandle(U8);
W_ U4 CopyFileExA(U1R,U1R,U8,U8,U4R,U4);
W_ U8 CreateFileA(U1R,U4,U4,U8,U4,U4,U8);
W_ U4 CreateProcessA(U1R,U1R,U8,U8,U4,U4,U8,U1R,STARTUPINFOA *R_,PROCESS_INFORMATION *R_);
W_ void ExitProcess(U4);
W_ U4 ReadFile(U8,U1R,U4,U4R,U1R);
W_ U4 SetFilePointer(U8,U4,U4R,U4);
W_ U4 WriteFile(U8,U1R,U4,U4R,U1R);
//
#define INVALID_HANDLE_VALUE (~U8_(0))
enum{
FILE_SHARE_WRITE=2,
GENERIC_READ=0x80000000,
GENERIC_WRITE=0x40000000,
OPEN_EXISTING=3};
//
// Initialized global data.
S_ U4 d[2]={0xDEADB175,0x01};
//
// Utility functions.
S_ U1 hex[16]={'0','1','2','3','4','5','6','7','8','9','a','b','c','d','e','f'};
S_ U1R Hex(U1R a,U4 v){a[0]=hex[v&15];return a+1;}
S_ U1R HexU1(U1R a,U4 v){Hex(a,v>>4);Hex(a+1,v);return a+2;}
S_ U1R HexU2(U1R a,U4 v){HexU1(a,v>>8);HexU1(a+2,v);return a+4;}
//
// Entry point.
O_ void main(U4 argc,U1R *R_ argv){
// If not called with arguments (base 'sme.exe' launch).
if(argc!=2){
// Copy 'sme.exe' to 'sme-cpy.exe'.
U4 c[1];CopyFileExA(U1R_("sme.exe"),U1R_("sme-cpy.exe"),0,0,U4R_(c),0);
// Launch 'sme-cpy.exe 1'.
S_ STARTUPINFOA si;
S_ PROCESS_INFORMATION pi;
si.cb=sizeof(STARTUPINFOA);
CreateProcessA(0,U1R_("sme-cpy.exe 1"),0,0,1,0,0,0,&si,&pi);
// Exit the process.
ExitProcess(0);}
// Called with arguments (the 'sme-cpy.exe 1' launch).
// Open access to standard output into console.
U8 f=CreateFileA(U1R_("CONOUT$"),GENERIC_WRITE,FILE_SHARE_WRITE,0,OPEN_EXISTING,0,0);
// Write out value after 0xDEADB175 to console.
U1 b[4]={'.','.','\n',0};HexU1(b,d[1]);
U4 r[1];WriteFile(f,U1R_(b),4,U4R_(r),0);
// Open 'sme.exe' for R/W, loop until this succeeds (just in case 'sme.exe' is still open for execute).
U8 h;while(1){h=CreateFileA(U1R_("sme.exe"),GENERIC_WRITE|GENERIC_READ,FILE_SHARE_WRITE,0,OPEN_EXISTING,0,0);
if(h!=INVALID_HANDLE_VALUE)break;}
// Read 'sme.exe' into memory, using something dumb (know file size is under 64 KiB).
S_ U4 m[16384];
ReadFile(h,U1R_(m),65536,U4R_(r),0);
// Find 0xDEADB175 offset (know this happens to be U4 aligned).
U4 o=0;while(o<16380){if(m[o]==0xDEADB175)break;o++;}o=o*4+4;
// Write out offset to console.
U1 b2[6]={'.','.','.','.','\n',0};HexU2(b2,o);
WriteFile(f,U1R_(b2),6,U4R_(r),0);
// Increment value after 0xDEADB175.
d[1]++;
// Write updated value to 'sme.exe'.
SetFilePointer(h,o,0,0);
WriteFile(h,U1R_((d+1)),4,U4R_(r),0);
// Close the file.
CloseHandle(h);
// Exit the process.
while(1)ExitProcess(0);}
________________________________________________________________________________________________________________________________
[PRG] PE Binary Header
PE
Building a simple 64-bit binary from scratch.
References.
Unfortunately Win 10 breaks compatibility with the small PE tricks which worked on Win 7 and prior.
Since I don't want to do my own custom importer
(due to the risk of Win 10 breaking that compatibility as well),
there is a gap of 5 cachelines between initial file headers and imports.
Overall this burns 5 cachelines total for headers and imports.
This is 80:1 bloat factor required to get a binary executing on Windows.
In an ideal machine the header would just be 4 bytes which gets replaced to a 32-bit pointer to a linker function,
with entry point at offset 4, and the entire binary loaded as R/W/E.
First 512 Bytes
Win10 requires minimum 512 offset and alignment for a section
(which is required to get imports).
So this packs non-import data into the first 3 cachelines using structure aliasing.
There is a 5 cacheline gap to the start of the imports which can be used for whatever the binary wants.
Unused fields are missing the '=' and are zero.
====================
IMAGE_DOS_HEADER
--------------------
{000} U2 e_magic=0x5A4D;
U2 e_cblp;
======================
IMAGE_NT_HEADERS64
----------------------
{004} U2 e_cp; U4 Signature='PE\0\0';
U2 e_crlc;
=====================
IMAGE_FILE_HEADER
---------------------
{008} U2 e_cparhdr U2 Machine=0x8664; // IMAGE_FILE_MACHINE_AMD64
U2 e_minalloc; U2 NumberOfSections=1;
{012} U2 e_maxalloc; U4 TimeDateStamp;
U2 e_ss;
{016} U2 e_sp; U4 PointerToSymbolTable;
U2 e_csum;
{020} U2 e_ip; U4 NumberOfSymbols;
U2 e_cs;
{024} U2 e_lfarlc; U2 SizeOfOptionalHeader=120; // Just two directories with aliasin
U2 e_ovno; U2 Characteristics=2; // IMAGE_FILE_EXECUTABLE_IMAGE
===========================
IMAGE_OPTIONAL_HEADER64
---------------------------
{028} U2 e_res[0]; U2 Magic=0x20b; // IMAGE_NT_OPTIONAL_HDR64_MAGIC
U2 e_res[1]; U1 MajorLinkerVersion;
U1 MinorLinkerVersion;
{032} U2 e_res[2]; U4 SizeOfCode;
U2 e_res[3];
{036} U2 e_oemid; U4 SizeOfInitializedData;
U2 e_oeminfo;
{040} U2 e_res2[0]; U4 SizeOfUninitializedData;
U2 e_res2[1];
{044} U2 e_res2[2]; U4 AddressOfEntryPoint=604; // Start the repair tool
U2 e_res2[3];
{048} U2 e_res2[4]; U4 BaseOfCode;
U2 e_res2[5];
{052} U2 e_res2[6]; U8 ImageBase=0x400000; // 4 MiB offset
U2 e_res2[7];
{056} U2 e_res2[8];
U2 e_res2[9];
{060} U4 e_lfanew=4; U4 SectionAlignment=4;
{064} U4 FileAlignment=4;
{068} U2 MajorOperatingSystemVersion;
U2 MinorOperatingSystemVersion;
{072} U2 MajorImageVersion;
U2 MinorImageVersion;
{076} U2 MajorSubsystemVersion=4; // WinNT Win32 version
U2 MinorSubsystemVersion;
{080} U4 Win32VersionValue;
{084} U4 SizeOfImage=BINARY_SIZE;
{088} U4 SizeOfHeaders=512;
{092} U4 CheckSum;
{096} U2 Subsystem=3; // IMAGE_SUBSYSTEM_WINDOWS_CUI
U2 DllCharacteristics;
(100} U8 SizeOfStackReserve;
{108} U8 SizeOfStackCommit=0x100000; // 1 MiB
{116} U8 SizeOfHeapReserve;
{124} U8 SizeOfHeapCommit=0x100000; // 1 MiB
{132} U4 LoaderFlags;
{136} U4 NumberOfRvaAndSizes=2; // Required to to get import table
{140} U8 DataDirectory[0]=0; // Exports needs to be empty
========================
IMAGE_SECTION_HEADER
------------------------
{148} U1 Name[8]; U4 DataDirectory[1].VirtualAddress=540; // Imports
{152} U4 DataDirectory[1].Size=40; // Enough for 2 entries
{156} U4 VirtualSize=BINARY_SIZE-512;
{160} U4 VirtualAddress=512;
{164} U4 SizeOfRawData=BINARY_SIZE-512;
{168} U4 PointerToRawData=512;
{172} U4 PointerToRelocations;
{176} U4 PointerToLinenumbers;
{180} U2 NumberOfRelocations;
U2 NumberOfLinenumbers;
{184} U4 Characteristics=0xE0000060;
// IMAGE_SCN_CNT_CODE|
// IMAGE_SCN_CNT_INITIALIZED_DATA|
// IMAGE_SCN_MEM_EXECUTE|
// IMAGE_SCN_MEM_READ|
// IMAGE_SCN_MEM_WRITE
{188} U4 Unused
==============
FREE SPACE
--------------
{192} to {511} - 5 cachelines.
The One Section
This provides the imports and the rest of the binary code and data.
I kept all the import data in the section instead of attempting to place it in the prior 512 byte header,
just in case Windows checks VA to section range.
This part packs the mess of PE import tables and string data into 2 cachelines.
It aliases many of the structures based on knowing parts that are not accessed.
The "repair tool" copies the function pointers 16 bytes earlier,
then restores the original IMAGE_IMPORT_BY_NAME RVAs as would be seen on disk.
This enables the header in memory to be stored back to an executable and still function properly.
The IMAGE_IMPORT_BY_NAME is tricky because it wants 16-bit alignment and two leading zeros.
======================
FUNCTION ADDRESSES
----------------------
{512} U8 LoadLibraryA
{520} U8 GetProcAddress
======================
IMAGE_THUNK_DATA64
----------------------
{528} U8 Function=588; // Offset to "LoadLibraryA"
{536} U8 Function=558; // Offset to "GetProcAddress" U4 unused;
===========================
IMAGE_IMPORT_DESCRIPTOR
---------------------------
U4 OriginalFirstThunk;
{544} U8 Function=0; // End IAT U4 TimeDateStamp;
U4 ForwarderChain;
{552} U4 Name=580; // Offset to "kernel32"
========================
IMAGE_IMPORT_BY_NAME
------------------------
U1 unused[2]; U4 FirstThunk=528; // Offset to Import Address Table
U1[2]='\0\0'
{560} U1[4]='GetP' U4 OriginalFirstThunk;
U1[4]='rocA' U4 TimeDateStamp;
{568} U1[4]='ddre' U4 ForwarderChain;
U1[4]='ss\0\0'; U4 Name;
{576} U4 FirstThunk=0; // Final entry must be empty
U1[4]='kern'
{584} U1[8]='el32\0\0Lo'
{592} U1[8]='adLibrar'
{600} U1[4]='yA\0\0';
===============================
REPAIR TOOL AND ENTRY POINT
-------------------------------
{604} b8 10 02 40 00 mov eax,0x400210; // Start of IMAGE_THUNK_DATA
{611} 48 8b 18 mov rbx,QWORD PTR [rax]; // Fetch LoadLibrary pointer
{612} 48 89 58 f0 mov QWORD PTR [rax-0x10],rbx; // Store at [512]
{616} 2E 48 c7 00 4c 02 00 00 mov QWORD PTR cs:[rax],0x24c; // Restore string RVA
{624} 48 8b 58 08 mov rbx,QWORD PTR [rax+0x8]; // Fetch GetProcAddress pointer
48 89 58 f8 mov QWORD PTR [rax-0x8],rbx; // Store at [520]
{632} 48 c7 40 08 2e 02 00 00 mov QWORD PTR [rax+0x8],0x22e; // Restore string RVA
=============
APP START
-------------
{640}
Builder Example
The following C code will build a quick proof of concept binary.
//
// SIMPLE SELF-CONTAINED GCC 'C' BASED WIN32 BINARY BUILDER
//
// Test with,
// gcc b64.c -march=amdfam10 -std=gnu11 -Ofast -o b64.exe -s -lkernel32 -luser32 -lgdi32 -lwinmm
// b64.exe
// tst.exe
// echo %ERRORLEVEL%
//
// Language tools.
#define E_(x,y) __builtin_expect(x,y)
#define O_ __attribute__((noreturn))
#define R_ __restrict
#define S_ static
#define W_ __attribute__((__stdcall__)) __attribute__((__force_align_arg_pointer__))
//
// Type system.
typedef unsigned char U1;
typedef unsigned short U2;
typedef unsigned int U4;
typedef unsigned long long U8;
typedef U1 *R_ U1R;
typedef U2 *R_ U2R;
typedef U4 *R_ U4R;
typedef U8 *R_ U8R;
#define U1R_(x) ((U1R)(x))
#define U2R_(x) ((U2R)(x))
#define U4R_(x) ((U4R)(x))
#define U8R_(x) ((U8R)(x))
#define U1_(x) ((U1)(x))
#define U2_(x) ((U2)(x))
#define U4_(x) ((U4)(x))
#define U8_(x) ((U8)(x))
//
// Win32 API for x86-64.
W_ U4 CloseHandle(U8);
W_ U8 CreateFileA(U1R,U4,U4,U8,U4,U4,U8);
W_ void ExitProcess(U4);
W_ U4 SetFilePointer(U8,U4,U4R,U4);
W_ U4 WriteFile(U8,U1R,U4,U4R,U1R);
//
#define INVALID_HANDLE_VALUE (~U8_(0))
enum{
CREATE_ALWAYS=2,
FILE_SHARE_WRITE=2,
GENERIC_READ=0x80000000,
GENERIC_WRITE=0x40000000};
//
// Entry point.
O_ void main(U4 argc,U1R *R_ argv){
// Building a 64 KiB binary (lots of extra space for later).
// This defaults to zero fill (so zeros need not be written).
#define BINARY_SIZE 65536
S_ U8 buf[BINARY_SIZE/8];
U1R b=U1R_(buf);
//
U2R_(b+0)[0]=0x5a4d; // e_magic
//
U1R_(b+4)[0]='P'; // Signature
U1R_(b+4)[1]='E';
//
U2R_(b+8)[0]=0x8664; // Machine
U2R_(b+10)[0]=1; // NumberOfSections
U2R_(b+24)[0]=120; // SizeOfOptionalHeader
U2R_(b+26)[0]=2; // Characteristics
//
U2R_(b+28)[0]=0x20b; // Magic
U4R_(b+44)[0]=604; // AddressOfEntryPoint
U8R_(b+52)[0]=0x400000; // ImageBase
U4R_(b+60)[0]=4; // SectionAlignment and e_lfanew
U4R_(b+64)[0]=4; // FileAlignment
U2R_(b+76)[0]=4; // MajorSubsystemVersion
U4R_(b+84)[0]=BINARY_SIZE; // SizeOfImage
U4R_(b+88)[0]=512; // SizeOfHeaders
U2R_(b+96)[0]=3; // Subsystem
U8R_(b+108)[0]=0x100000; // SizeOfStackCommit
U8R_(b+124)[0]=0x100000; // SizeOfHeapCommit
U4R_(b+136)[0]=2; // NumberOfRvaAndSizes
U4R_(b+148)[0]=540; // DataDirectory[1].VirtualAddress
U4R_(b+152)[0]=40; // DataDirectory[1].Size
//
U4R_(b+156)[0]=BINARY_SIZE-512; // VirtualSize
U4R_(b+160)[0]=512; // VirtualAddress
U4R_(b+164)[0]=BINARY_SIZE-512; // SizeOfRawData
U4R_(b+168)[0]=512; // PointerToRawData
U4R_(b+184)[0]=0xE0000060; // Characteristics
//
U8R_(b+528)[0]=588; // Function
U8R_(b+536)[0]=558; // Function
U4R_(b+552)[0]=580; // Name
U4R_(b+556)[0]=528; // FirstThunk
//
U1R_(b+560)[0]='G';
U1R_(b+560)[1]='e';
U1R_(b+560)[2]='t';
U1R_(b+560)[3]='P';
U1R_(b+560)[4]='r';
U1R_(b+560)[5]='o';
U1R_(b+560)[6]='c';
U1R_(b+560)[7]='A';
U1R_(b+560)[8]='d';
U1R_(b+560)[9]='d';
U1R_(b+560)[10]='r';
U1R_(b+560)[11]='e';
U1R_(b+560)[12]='s';
U1R_(b+560)[13]='s';
//
U1R_(b+580)[0]='k';
U1R_(b+581)[0]='e';
U1R_(b+582)[0]='r';
U1R_(b+583)[0]='n';
U1R_(b+584)[0]='e';
U1R_(b+585)[0]='l';
U1R_(b+586)[0]='3';
U1R_(b+587)[0]='2';
//
U1R_(b+590)[0]='L';
U1R_(b+591)[0]='o';
U1R_(b+592)[0]='a';
U1R_(b+593)[0]='d';
U1R_(b+594)[0]='L';
U1R_(b+595)[0]='i';
U1R_(b+596)[0]='b';
U1R_(b+597)[0]='r';
U1R_(b+598)[0]='a';
U1R_(b+599)[0]='r';
U1R_(b+600)[0]='y';
U1R_(b+601)[0]='A';
//
U1R_(b+604)[0]=0xb8;
U1R_(b+604)[1]=0x10;
U1R_(b+604)[2]=0x02;
U1R_(b+604)[3]=0x40;
U1R_(b+604)[4]=0x00;
//
U1R_(b+604)[5]=0x48;
U1R_(b+604)[6]=0x8b;
U1R_(b+604)[7]=0x18;
//
U1R_(b+604)[8]=0x48;
U1R_(b+604)[9]=0x89;
U1R_(b+604)[10]=0x58;
U1R_(b+604)[11]=0xf0;
U1R_(b+604)[12]=0x2e;
U1R_(b+604)[13]=0x48;
U1R_(b+604)[14]=0xc7;
U1R_(b+604)[15]=0x00;
U1R_(b+604)[16]=0x4c;
U1R_(b+604)[17]=0x02;
U1R_(b+604)[18]=0x00;
U1R_(b+604)[19]=0x00;
//
U1R_(b+604)[20]=0x48;
U1R_(b+604)[21]=0x8b;
U1R_(b+604)[22]=0x58;
U1R_(b+604)[23]=0x08;
//
U1R_(b+604)[24]=0x48;
U1R_(b+604)[25]=0x89;
U1R_(b+604)[26]=0x58;
U1R_(b+604)[27]=0xf8;
//
U1R_(b+604)[28]=0x48;
U1R_(b+604)[29]=0xc7;
U1R_(b+604)[30]=0x40;
U1R_(b+604)[31]=0x08;
U1R_(b+604)[32]=0x2e;
U1R_(b+604)[33]=0x02;
U1R_(b+604)[34]=0x00;
U1R_(b+604)[35]=0x00;
//
// Extra code to return lower 32-bits of GetProcAddress
// mov rax,rbx; ret;
U1R_(b+640)[0]=0x48;
U1R_(b+640)[1]=0x89;
U1R_(b+640)[2]=0xd8;
U1R_(b+640)[3]=0xc3;
//
// Dump binary to file.
U8 h=CreateFileA(U1R_("tst.exe"),GENERIC_WRITE|GENERIC_READ,FILE_SHARE_WRITE,0,CREATE_ALWAYS,0,0);
U4 r[1];WriteFile(h,U1R_(buf),BINARY_SIZE,U4R_(r),0);
CloseHandle(h);
// Exit the process.
while(1)ExitProcess(0);}
________________________________________________________________________________________________________________________________
[PRG] Linux?
Tried to get back to using Linux on a PC laptop, failed...
- F2 during boot to get into the BIOS (at least on this machine)
- Was forced to set a BIOS 'Supervisor Password' to disable Secure Boot (took a while to figure that one out)
- Disable Secure Boot
- Found I could disable BIOS passward again after disabling Secure Boot (so why require the password prior?)
- Disabled 'Fast Boot' but it get re-enabled after rebooting (what I'm supposed to go into BIOS each boot?)
- Turned off Win11's 'Fast Boot' from the control panel, but doesn't change the BIOS behavior
- Apparently there is no way to change the 'Boot Mode' to Legacy (damn, UEFI is a nightmare)
- Tried to install from Virtual Box but Windows keeps sleeping the USB thumb drive (seriously)
- Disabled 'USB selective suspend setting' (of course that didn't work)
- Downloaded 'Rufus' to try to make an Arch ISO thumb stick from this Windows machine (also broken)
- Bought a new thumb drive, even though the 'old' thumb drive is effectively new too
- Eventually got linux to run from Virtual Box
- Got blocked attempting to build a Linux thumb drive based system, wouldn't UEFI boot (probably config issue)
Where I left off on Arch install.
- cgdisk /dev/sda ... to create 3 partitions {0700 (for FAT32),ef00 (for EFI), 8304 (for /)}
- mkfs.fat -F 32 /dev/sda1
- mkfs.fat -F 32 /dev/sda2
- mkfs.ext4 -O "^has_journal" /dev/sda3
- mount /dev/sda3 /mnt
- mount --mkdir /dev/sda2 /mnt/boot
- pacstrap -K /mnt base linux linux-firmware
- genfstab -U /mnt >> /mnt/etc/fstab
- arch-chroot /mnt
- ln -sf /usr/share/zoneinfo/America/New_York /etc/localtime
- hwclock --systohc
- pacman -S nano
- nano /etc/locale.gen and uncomment en_US.UTF-8 UTF-8
- locale-gen
- nano /etc/locale.conf and add LANG=en_US.UTF-8
- nano /etc/hostname and add ihatelinuxtoo
- passwd and set password
- pacman -S grub
- grub-install --target=x86_64-efi --efi-directory=/boot --removable --recheck
- exit
- umount -R /mnt
- reboot
Random Notes
________________________________
[PIX] Resolution vs Pixel
Q. Why Does an LCD Need Much Higher Resolution Than a CRT?
Because of physical pixel shape.
CRT's pixels have smooth partial overlap.
CRT can reproduce a smooth signal with less physical resolution.
LCD's pixels are quite hard,
LCD requires a substantially larger amount of resolution
to get to the point where the pixel's hard edge is not perceptual.
Q. Why Does the LCD Hard Pixel Fail Even For Text Rendering?
Because a substantial amount of parts of characters in a font are not just horizontal or vertical,
or not pixel aligned.
LCD hard pixel can only reproduce a higher frequency than physical resolution hard edge on axis and pixel aligned features.
Q. For Moving Images With No Temporal Aliasing, Why is Minimum Feature Size Larger Than a Pixel?
Pixel sized features with sub-pixel motion would alternate between
being visible when aligned to pixel centers,
to being half visible when aligned to pixel edges,
or quarter visible if the feature is a point aligned to a pixel corner.
This visibility change is the temporal aliasing.
The only way to reduce temporal aliasing is to drop off contrast of pixel sized features until
the visibility change is not perceptual any more.
This is the standard for film rendering,
and a requirement to provide a believable image.
Q. Would Phone OEMs Push Peak Resolution Images?
Pushing peak resolution sensor is fine,
but the images generated with such a sensor don't actually provide pixel quality at peak resolution.
Images could easily be scaled down substantially and end up with higher quality as artifacts get removed in the process.
The aim of keeping images at peak resolution is to more quickly fill the phone's storage,
since phone companies get margin on higher storage phones,
or optionally push customers into cloud services with aim to charge a higher monthly fee.
________________________________________________________________________________________________________________________________
[PIX] DLSS3?
Notes from the original DLSS3 launch in 2022 ...
Related Links
Summary, as a game developer I would never choose to integrate DLSS3 into one of my games.
- Added Latency of Extra Reconstruction -
Temporal interpolation (doubling) happens at present time.
Run logic to generate the interpolated frame, present that.
Queue up the game rendered frame to present next.
So at a minimum the time to generate the interpolated frame is added to latency.
- Added Latency of Interpolation -
Button to muzzle flash wouldn't see a latency add, because the interpolated frame would show some amount of the effects of the muzzle flash.
However camera motion would see around a half input frame latency add,
because the first frame is only half to the rendered frame.
It is likely that most reviews miss the point that camera motion latency is worse than button to flash measurements with temporal frame interpolation.
- Jittered Motion -
DLSS3 depends on Variable Refresh Rate (VRR).
DLSS3 latency is substantially worse with V-Sync enabled.
However VRR can never produce consistent linear motion,
so it is NOT acceptable from an ultimate quality perspective.
The amount of motion jitter is relative to both the variability of time it takes to render a frame, and the frame rate of the display.
- Power Hungry -
The associated latency reduction technology depends on keeping the GPU at peak power,
to minimize the time it takes to render a frame.
This is would not be a good strategy for laptops for example.
- BFI is Better to Reduce Motion Blur -
At the high frame rates which DLSS3 starts to have lower perceptual artifacts and more acceptable input latency,
v-sync with black frame insertion is a better technology to reduce the perceptual motion blur caused by scan-and-hold displays than simply increasing frame rate.
________________________________________________________________________________________________________________________________
[PIX] Morphological AA Links
Despite temporal techniques, spatial AA is still useful when overriding areas of low convergence ...
________________________________________________________________________________________________________________________________
[PIX] Modified Soft BFI
Display rates to BFI configurations?
- 360 Hz ... 90 Hz (/4)
- 240 Hz ... 80 Hz (/3)
- 144 Hz ... 72 Hz (/2)
- 120 Hz ... 60 Hz (/2) ... Probably not useful?
"Modified"
Soft BFI is probably limited by non-linearity in display pixel transitions.
Meaning {white,black} frames won't necessarily average to {50% grey}.
The other issue is the loss of brightness.
Assuming enough pixel response linearity,
one could redistribute light across frames.
Start with repeating the input frame N times on output.
Could increase brightness of pixels which are not at peak already,
and then subtract that amount from the later frame(s).
Thus temporal energy conservation.
At white, this would act as scan-and-hold,
but say at 144 Hz, anything under 50% would act as 72 Hz with BFI.
________________________________
[CRT] Links Inventory Misc
TODOs
Links
Downsampling
Signals
VGA (RGBHV)
- RGB {0 to 0.7V} 75 Ohm, pin {1,2,3}
- HV {0 to 5.0V} TTL compatible, pins {H=13, V=14}
- BNC cable {H=grey/yellow, V=white/black}
- Pin 9 {5V}
SCART
RGB {0 to 0.7V} 75 Ohm termination, pin {15,11,7} (shared with component)
S (composite video, or just composite sync) {0 to 1V} 75 Ohm, pin {20}
NTSC
- TODO: Correct this documentation for half line!
- 15.734 kHz
- 29.97 (30/1.001) FPS
- 59.94 (60/1.001) FPS for 240p modes
- VERT
- 483 visible
- 2 line - front porch
- 6 line - sync
- 34 line - back porch
- 525 scanlines total
- HORZ
- 52.6 us - video
- 1.5 us - front porch
- 4.7 us - back porch
- 4.7 us - sync
- 10.9 us - blanking total (sum of porches and sync)
Modelines
Modeline data provided as {Display, Sync Start, Sync End, Total}
See: www.mythtv.org/wiki/Modeline_Database
Translator from modeline to AMD/NV PC driver settings:
Front Porch = Sync Start - Display
Sync Width = Sync End - Sync Start
Diagram:
|<----------------total-------------->|
|<------------sync-end----------->| .
|<---------sync-start------->| . .
|<-------display-------->| . . .
. . . . .
|XXXXXXXXXXXXXXXXXXXXXXXX|---|____|---|
. . .
front porch ....|<->| .
sync width .........|<-->|
Inventory
Compaq MV 740 - 17" VGA, {31-70kHz,50-120Hz}, offline, currently dead (won't power on).
- FREE IF ANYONE WANTS IT! - Don't have time to look into fixing it
Daewoo DTQ-20U4SC - 20" NTSC TV, like new
Dell UltraScan 1600HS Series D1626HT - 21" VGA {30-107kHz,48-160Hz}, made by Sony, good tube, cleaned
- TODO: Grab local copy of manual and service manual!
- Service Manual
- IN STORAGE - Don't have room on my desk right now
Dotronix DSV27 - 27" 480i, from Dotronix, new from new-old-stock LG tube
- The LG DU27FB32C insides destroy 240p signals, so this is a 480i only device
- Needs some re-calibration (new state not great)
- Overall not impressed, amazingly expensive, seems like it is just new LG TV in a new metal body
- Manual | Service Manual
- IN USE - Connected to PS2 via component
eMachines 17fs - 17" VGA, {30-70kHz, 50-160Hz}, new-old-stock
- Could use a film to improve black levels (not good ambient reflection)
- IN USE - Connected to AMD Laptop
Future Power 17DB88 - 17" VGA, {?-?kHz,?-?Hz}, new-old-stock
HP "1024" D2813 - 14" VGA, {?kHz,?Hz}, tube ok, cleaned
- OFFLINE - Need to track down sparking problem (maybe flyback)
- FREE IF ANYONE WANTS IT! - Don't have time to look into fixing it
Insignia IS-TV040919 - 20" NTSC TV, new-old-stock
- Manual | Service Manual
- Repaired the courier transform cracked PCB, got video, had problem with menu and controller not working?
- Reglued the flyback screw housing, but it didn't hold on reassembly
- Strengthened the plastic rails holding the board
- OFFLINE - Thought this was left in a working state actually (need to check again)
JVC AV-27D200 - 27" NTSC TV
- Manual
- OFFLINE - Cleaned, but board needs trace repair, so waiting on time to get stuff to do that
JVC i'ART 27" AV-27SF36 - 27" NTSC TV, new-old-stock
- OFFLINE - Going to use for 'arcade' setup
KDS KF-7b - 17" VGA, {30-70kHz, 50-160Hz}, new-old-stock
- Could use a film to improve black levels (not good ambient reflection)
- Plastic body disolves with isopropyl alcohol, so this ended up with a new 'artistic textured surface'
- IN USE - Connected to day job laptop
MakVision/Wei-YA M2929D4-TS SVGA Arcade Monitor - 29" VGA (480p/600p), {30-40kHz,47-90Hz}, new-old-stock
- Specs
- OFFLINE - Screen shows OSD, but HDFury Nano, and AMD VGA laptop not wanting to drive this now, was fine before
MakVision/Wei-YA M3129DS-LG CGA/EGA/VGA Arcade Monitor - 29" VGA (240p/480p), {15/24/31kHz,47-70Hz}, new-old-stock
MaxTech XT-4800 - 14" VGA, {30-48?kHz,?-87?Hz}, new-old-stock
Philips 20PT6341/37 - 20" 240p/480i
- This probably needs a re-cap and re-calibration
- Having trouble with service menu due to power button issues on remote, lost component input for some reason after a reboot
- Wanted to use this during game development for slot-mask 240p testing
- CRT Database |
Manual |
Service Manual
- OFFLINE - Until service menu issues are resolved
Philips 27PT6441/37 - 27" 240p/480i
- This is bright, might need recap and calibration
- Have GBS-C for this, intended to be a future home arcade display
- Manual |
Service Manual
- OFFLINE - Waiting for time to service (needs cleaning too)
Philips 32PT6441/37 - 32" 240p/480i
- This one needs tube scratch repair
- Cleaned, painted, recapped only the really bad caps
- Have GBS-C for this, intended to be a future home arcade display
- Manual |
Service Manual
- OFFLINE - Waiting for time to re-test
Philips 34PW850H37F - 34" 16:9 via Component (Does 480p/720p)
- Was intending to use this for SPC, but stalled as it is too heavy
- OFFLINE - Dropped this on my food, waiting until I have help to lift it (needs cleaning)
Sharp 32SC260 - 32" 240p/480i
- This is bright, might need recap and calibration
- Have GBS-C for this, intended to be a future home arcade display
- OFFLINE - Waiting for time to service
Sony BVM-D20F1U - 20" 4:3 multi-format
- This needs internal cleaning, and should be connected to a 480p source instead of SNES
- Not super bright, been recapped
- IN USE - Connected to SNES
Sony Multiscan CPD-E200 - 17" VGA {30-85kHz,48-120Hz}
- Sold!
- Cleaned, tube good, but prior owner damaged screen anti-glare coating
- Specs | Manual | Service Manual
- SOLD - This display has an agressively ringing horizontal sharpening which can not be turned off!
Sony PVM-8041Q - 8" 240p/480i
- This needs internal cleaning, preventive recap
- IN USE - Portable PVM
Sony PVM-1354Q - 13" 240p/480i (HR Tube, 16:9 Toggle)
- Needs a clean
- OFFLINE - Still "Portable" PVM, just not currently using
Sony PVM-14L2 - 14" 240p/480i (16:9 Toggle)
- Got a VGA board for this, need to try it
- This needs internal cleaning, calibration, preventive recap, and need to fix the power button (sticks)
- IN USE - Connected to PS1
Sony PVM-? / Olympus OEV203 - 19" 240/480i
- OFFLINE - Haven't had the time to get into this one
Sony PVM-1953ST - 19" 240/480i, Olympus (HR Tube, Endoscope Monitor)
- This has a good external cleaning
- This needs internal cleaning, calibration, preventive recap, and fix defaults to re-enable the knobs
- OFFLINE - Was using for GBS-C downscaling testing
Sony PVM-1953MD - 19" 240/480i (HR Tube)
- Needs to be cleaned
- OFFLINE - Haven't had the time to get into this one
Sony PVM-20M2U - 20" 240/480i (16:9 Toggle)
- This came with mostly unfunctional front buttons, need to fix that
- Has some convergence issues on bottom half of screen
- This was a smoker owned CRT (will never buy those again)
- Cleaned, put back together without some front buttons, need a chopstick to use
- Added a destructive interference anti-reflective film to tube, works great
- OFFLINE - Still needs recap
Sony PVM-20M2MDU - 20" 240/480i
- OFFLINE - Good display, but rusted chassis (need to restore)
Sony PVM-20M2MDU/ST - 20" 240/480i
- This needs internal cleaning, and preventive recap
- Bright, like new, probably needs slight calibration, doesn't have an HR tube (but like it that way)
- IN USE - Connected to NeoGeo MVS + Supergun
Sony Wega KD-34XBR970 - 34" 1080i HD TV
- This does 720p but has some lag, so it is intended to be used for Netflix/etc in a bedroom
- Very bright
- Also a backup in case the 30" HDTV dies
- OFFLINE - Waiting for time to clean, recap, and calibrate
Sony Wega KV-30HS420 - 30" 1080i HD TV
ViewSonic 17GS - 17" VGA {30-69kHz,50-160Hz}, new-old-stock
- IN USE - Connected to NV Laptop
ViewSonic G75f - 17" VGA {30-86kHz,50-180Hz}, cleaned, tube ok
- OFFLINE - Plastic is self-destructing, needs a new external chassis
ViewSonic Optiquest Q95 - 19" VGA {30-86kHz,50-160Hz}, cleaned, good tube
- Manual
- OFFLINE - Need to fix front buttons
ViewSonic PS790 - 19" VGA {30-95kHz,50-180Hz}, cleaned, medium tube life
________________________________________________________________________________________________________________________________
Insignia
This required a lot of fixes to bring back to life.
 UPS Transform, Old New Stock TVs Are Bad Out of the Box, then Finally Warm and Calibrated
UPS Transform, Old New Stock TVs Are Bad Out of the Box, then Finally Warm and Calibrated

 Cracked, and Repaired (Different Parts of the Same Board)
Cracked, and Repaired (Different Parts of the Same Board)
________________________________________________________________________________________________________________________________
Endoscopy PVM
Have too many PVMs.

 Ebay Endoscopy PVM-1953ST, Picked Up Via Freight, Clean Outside (Bad SNES Running 240p Test)
Ebay Endoscopy PVM-1953ST, Picked Up Via Freight, Clean Outside (Bad SNES Running 240p Test)
________________________________________________________________________________________________________________________________
First Philips
For the love of slot mask.
 Philips 20PT6341/37 - Deceptively Clean on the Inside, Might Need a Recap (Probably SNES That Needs Recap)
Philips 20PT6341/37 - Deceptively Clean on the Inside, Might Need a Recap (Probably SNES That Needs Recap)
________________________________
[CRT] Notes
Misc
Intergraph Interview 28hd98 Model TX-D8W71W
Mitsubishi's Diamond Pro 2070SB (VGA, 140 kHz, 160 Hz)
- CRT Database
- Also: NEC FP2141SB, HP P1230, LaCie Electron 22 Blue IV, SGI C220
NEC DM-2000P
________________________________________________________________________________________________________________________________
APEX/KLH
- Some 'Apex PF3220 / KLH KF3228' have a Toshiba Microfilter tube (purple tint)!

- PF2025 with component looks great

- [RGB] AT2704S
- [RGB] AT2408S

________________________________________________________________________________________________________________________________
Daewoo
________________________________________________________________________________________________________________________________
JVC
Earlier (240p | 480i)
D-Series (240p | 480i)
- Always interested in pre-2001 JVCs for arcade monitor!
- 1999 had higher quality electronics
- 2001 27" models lacked full geometry adjustment
- Best are model numbers ending in 0
- The non D-Series has the same internals
- Non-component JVCs can typically be easily RGB modded
- RGBable: AV-32D503 AV-32D303 AV-32D203 AV-20D202 AV-36D501 AV-36D201 AV-32D501 AV-32D201 AV-27D501 AV-27D201
- [RGB] Poor description
- [RGB] AV-32D501
- [RGB] AV-27020
- Non-RGBable: AV-36320 AV-36330 AV-36360 AV-36S33 AV-36S36
JVC DT-V (15-45 kHz, 50-100 Hz)
JVC I'Art (240p | 480i)
JVC I'Art Pro (HD)
________________________________________________________________________________________________________________________________
Orion
________________________________________________________________________________________________________________________________
Panasonic
Panasonic TX80P300A
________________________________________________________________________________________________________________________________
Philips / Magnavox
No Component (240p | 480i)
Curved With Component (240p | 480i)
Flat With Component (240p | 480i)
Wide Screen 16:9 SD Model (240p | 480i)
- Do these have aspect controls, can they do 480p, etc?
- 26PW6341/37 and 30PW6341/37, better voltage regulation (compared to the 4:3 TVs)
TODO....
Philips 32PT740H/37A (240p | 480i | 480p | VGA)
- Curved 4:3 supporting HD resolutions
Philips 32PT830H/37A (240p | 480i | 480p | VGA)
- Non-Curved 4:3 supporting HD resolutions
Philips 30PW862H (240p | 480i | 480p)
- 16:9 set with RGB-HV input
Philips 34PW8520 (240p | 480i | 480p | VGA)
Presentation Monitors (VGA)
- Would grab one if I could find one, super rare!
- 4:3 with 31kHz, says 'Multimedia Display' in lower left
- PD-5029-S (640x{480,400,350}), PS1127 PS1132 (up to 1024x768), 32PD8000 (480p, 600p)
________________________________________________________________________________________________________________________________
Prima/Advent/Jensen
- Prima China brand, rebrand as Advent and Jesen
- Advent Q1435A: Confirmed slot mask with no processing and component inputs
- Advent HT3061A: HDTV 480p and 1080i over component and DVI. Lag? 240p?
________________________________________________________________________________________________________________________________
RCA
MM Series
- Pickup anything with the 'digital|HI-RES' label in the upper right!
- MM27100 MM36100 - MM27110 MM32110 MM36110
- Lowendmac.com article on MM36100
- MM36100 Manual
- MM36100 36" and does {480p, 600p, 1080i} via VGA
- Later MM100's (MM36110) did {480p, 1080i} over component (earlier didn't)

4:3 Proscan
- Cound be interesting, but won't find one of these!
- Could do 1024x768 interlaced at 86Hz
- PS32800HR PS36800HR PS36810 PS32810 PS27810
Misc
- Some to avoid, some never to be found!
- Curved HD and HD Proscan - F38310 (does scaling), PS38000 (?), etc, confusing (scale or not)
- Xbox Ready Models (SD Component) F27650 F32650 - Looks good
- Home Theatre Premiere F36715 - Looks like component has sharpening, is it defeatable?
- SDTV (Curved) - Looks like component has sharpening, is it defeatable?
- SDTV Truflat - Looks like component has sharpening, is it defeatable?
- HDTV Truflat [4:3] - D36TF30 (480p VGA) D27F570T
- HDTV Truflat [16:9] - Scenium D34W135D (480p DVI), Dish HD34-300/310 (480p DVI)
________________________________________________________________________________________________________________________________
Samsung
Samsung Curved (240p | 480i)
Samsung Dynaflat
- Avoid, these all have sharpening which cannot be turned off even in the service menu!
- EDTV/HDTV models deinterlaced 240p/480i with lag
- TXN3271HF
- 480p and 1080i are lag free
Samsung SlimFit
________________________________________________________________________________________________________________________________
Sanyo
________________________________________________________________________________________________________________________________
Sharp
Non-Component (240p | 480i)
Cinema Select (240p | 480i)
- Seems worth trying!
- Label upper left, need the remote, or redi-remote (with component input button)
- Other models of this era didn't have component, and some look identical except for the label
- [Component] 27K-X2000 31HX1000 31HX1200 35HX1000 35HX1200 36K-X2000 CK36S60
Curved With Component (240p | 480i)
Sharp X-Flat (240p | 480i)
________________________________________________________________________________________________________________________________
Sony
Sony BVM | PVM
Sony KV-20XBR / KV-25XBR
- My parents had one of these (1985), absolutely amazing (RGB inputs)
Sony FW900 (VGA)
Sony Curved (240p | 480i)
Sony Wega (240p | 480i)
- Only interested in ones which can get RGB mod!
- [RGB BA-5] KV-20FS12 KV-20FV12 KV-21FE12 KV-21FM12 KV-27FS13 KV-27FS17 KV-27FV17 KV-29FV17 KV-32FS13 KV-32FS17 KV-34FS17
- Suggesting RGB mod because sharpening disable isn't fully effective
- FV310 claimed to be the best (higher quality regulators): KV-36FV310 KV-32FV310 KV-27FV310
- [noCOMPONENT] KV-27FV15 KV-24FV12 KV-24FV10 KV-20FV12
- [RGB 38"] KV-38FS200 KV-38FV250 KV-38FV310
- [RGB 36"] KV-36FS100 KV-36FS200 KV-36FS210 KV-36FV300 KV-36FV310
- [RGB 34"] KV-34FS17 KV-34FS100 KV-34FS100 KV-34FV250 KV-34FV310
- [RGB 32"] KV-32FS13 KV-32FS17 KV-32FS100 KV-32FS200 KV-32FS210 KV-32FV300 KV-32FV310
- [RGB 29"] KV-29FA210 KV-29FS100 KV-29FS100 KV-29FV17 KV-29FV300 KV-29FV300 KV-29FV310
- [RGB 27"] KV-27FS13 KV-27FS17 KV-27FS100 KV-27FS210 KV-27FV17 KV-27FV300 KV-27FV310
- [RGB 24"] KV-24FV10 KV-24FV12
- [RGB 21"] KV-21FE12 KV-21FM12
- [RGB 20"] KV-20FA210 KV-20FS12 KV-20FV10 KV-20FV12
- [RGB 13"] KV-13FM12 KV-13FM13 KV-13FM14
- [noRGB 27"] KD-27FS170 KV-27FS100L KV-27FS120
- [noRGB 24"] KV-24FS100 KV-24FS120 KV-24FV300
- [noRGB 20"] KV-20FS100 KV-20FS120 KV-20FV300
- [noRGB 13"] KV-13FS100 KV-13FS110
Sony Wega (Hi-Scan)
- These are all 1080i, don't get except for 16x9, as they don't have real 240p modes!
- [16:9] KD-34XBR970 KV-34HS420N KV-34HS420 KV-30HS420
- [16:9 noHDMI] KV-34XBR800 KV-34HS510 KV-30HS510 KD-34XB2 KW-34D1 - The ones with DVI might do 480p 16:9 native, but with lag
- [4:3] KV-40XBR800 KV-36XBR800 KV-36HS510 KV-36HS500 KV-36HS420 KD-32XS945
- [4:3] KV-32HS420 KV-32XBR800 KV-32HS510 KV-32HS500 KV-32HV600 KV-27HS420
- [4:3] KV-40XBR700 KV-36XBR450H KV-36XBR450 KV-36XBR400
- [4:3] KV-36HS20 KV-32XBR450 KV-32XBR400 KV-32HS20
Sony Wega (Super Fine Pitch)
________________________________________________________________________________________________________________________________
Sylvania
________________________________________________________________________________________________________________________________
Toshiba
- 1990 'Lavender Mask' had lower ambient reflection, results in purple ambient tint
- 1995 'Microfilter' had higher contrast
SD
- Anything 1997-1999 with component and a 'Cinema Series' logo on front would be nice to have!
- 'FST PERFECT' tubes in Cinema Series line (best), 'FST BLACK' in 32"/35"/36" 'SuperTUBE'
- 1997 CN36G97 first NA TV with component inputs and 'FST PERFECT' tube
- 1999 CN36Z71 possibly the last SD 'FST PERFECT' tube
- True Toshiba has a square info tag on back
HD
- Maybe a pre-2003 TV for 480p
- All 16:9 HD sets until 2004 had 'Microfilter', no 3:4 HD sets had it
- 2000 CW34X92 had no SD (line doubled), no 720p, but lag-free 480p
- 2003 everything up-scaled to 1080i/540p
- The 'timm' doesn't have a 'Microfilter' tube, but does 15kHz and 31kHz
Orion
________________________________________________________________________________________________________________________________
Zenith
________________________________
[CSS] Test Area
Heading Two
- Bold text
- Hyperlink
- Italic text
- Normal text
- Monospace
Preformated text
 Image Caption
Image Caption
________________________________
[Truck]
Life of the 1999 Manual Cummins Diesel Dodge 3500 Dually ...
TODO
- [ ] Replace diffs
- [ ] Rear LSD is starting to go, figure out replacement diffs
- [ ] Fix passenger window mechanism (catching)
- [ ] Have shop install clutch and flywheel
- [ ] Wipe out inside of truck
- [ ] Switch to undertank diesel send, fix fuel gauge send
- [ ] Replace filters on lift pump
- [ ] Track down interior bubbling sound (heater core maybe)
- ---
- [x] Vacume/clean inside
- [x] Fill up tires
- [x] Fix non-accessable air stem
- [x] Take to shop
- [x] What motor: "1998.5-2002 trucks , have the 5.9L Cummins engine with 24 valves"
- [x] What gearbox: "NV4500 5-Speed Manual"
- [x] How much power does it make? (was 256/460 hp/lb-ft, estimated 400/880 with quad+injectors)
- [x] Order clutch: NMU70279-04-5SCE - Ceramic single disc from Valair
- [x] Hows ceramic? ... Youtuber says it's fine towing
- [x] Replace passenger window mechanism
________________________________
[Jeep]
Life of the 2016 Jeep Unlimited Rubicon ...
TODO
- [ ] Replace the tires.
- [ ] Get 2016 Willy ECU, because some of those didn't have electronic key.
- [ ] Fix front turn bulb.
- [ ] Root the electrical problem.
- [ ] Remove remaining fuses that are not required for basic functionality.
- [ ] Battery died again, remove rest of non-necessary fuses.
- [ ] Cut out remaining unused old seat belt retractors, star bolt not able to open.
- [ ] Cut off metal tabs for front fenders.
- [ ] Look into front bumber with winch?
- [ ] Fix rust and paint.
- [ ] Remove body fender (requires new attachment for hood latch, or no hood).
- [ ] Cut off front bumber excess (requires clean and paint cut edges).
- [ ] Remove wheel speed sensors (already have fuse out, no more MPH reading).
- [ ] Remove parking brake lines to back wheels.
- [ ] Tube the door area, install mesh to avoid de-arm on rollover.
- [ ] Metalcloak 3.5" lift?
- ---
- [x] Order Rust Kutter and SteelIt for metal repair (and acetone).
- [x] Order new tires.
- [x] Charging battery (trying to save it).
- [x] 2023 change all fluids (trans, diff, gearbox, etc).
- [x] Starter died, replace starter, hopefully that fixes electrical problem (nope).
- [x] Installed bypass for nany (Searchers Rubicon Locker Override JK kit).
- [x] Replaced rear seatbelts too, 3 Point Seat Belt - Non-Retractable, from SeatBeltsPlus.com.
- [x] Sold OEM wheels and tires.
AC Delete and Rewire (2020)
Airbags except from the seats have been removed.
AC has been removed except the compressor due to not being able to find an idler pulley replacement.
The console metal frame was cut out except for the driver's side.
The console itself was cut out except just the part infront of the driver side.
All inside wiring was minimized, with all electrical tape removed, and rewrapped in a nice sleve.
At fisrt I had gone to far in stripping out wiring,
to the point where the jeep wouldn't start.
Got an ORB2 scanner, only had a U110A code, which mapped to steering angle sensor fail.
Also had the security dot on the dash, so knew I snipped out that bus on accident.
Those both share the same bus, so found the wires (without a manual),
and resolder and shrink wrapped in a correction.
Jeep started up without any problem after that.
Have a bunch of wiring left to do (the other side of the firewall, replace the giant terminal with something smaller, etc).
 A Lot More Room For Groceries
A Lot More Room For Groceries
Aero Wheel Install (2020)
The beadlock is different than other aluminum offroad wheels, there is no lip to center the tire,
and I suspect the Patagonia tires have a thicker bead than dirt track racing wheels.
Mounting beadlock seemed strange at first, but after all the bolts had been torqued down, everything seems fine.
There are less and larger bolts for the Aero wheels, but they have higher torque specs (30-35 ft-lbs).
Easy but time consuming to mount the tire.
Took about 3 psi to get the tire to seat past the safety ridge on the rim.
Running 20 psi now for the street.
Might adjust after I get enough miles to retorque the bolts.
 Rear
Rear
 Front
Front
 Front Inside
Front Inside
Possible Mistake (2020)
The 15"x8" wheels are rated for 3500 lbs circle track racing.
JKU stock is a pig at around 4500 lbs.
The 15"x10" wheels are rated for 4000 lbs.
Probably should have gone with the 15"x10" wheels.
Instead going to continue to lighten the jeep.
Aero Wheel Evaluation (2020)
Bought a single Aero 53 Series Wheel from Summit for evaluation.
This is a 15"x8" with 3" of backspacing with a 5x5 bolt pattern for the JKU.
Fits just fine without any grinding of the caliper for my 2016 JKU. Lots of clearance.
HSLA steel and only 23 lbs for the wheel.
Went and ordered the other 3, only $137/wheel from Summit.
Seat Covers (2020)
Went with Bartact Base Line Performance seat covers.
Wanted something minimal that would offer enough protection to keep the Jeep doors-free for most of the year.
Like the extra zipper pouch in the front, easy to put wallet and phone in there so I don't have to worry about it falling out of the shorts.
Tire Research For 15" Wheels (2020)
Turns out no affordable 37" tire for 15x9, so 35" is as big as this story goes!
General notes.
Federal Couragia M/T Mud-Terrain
- $224 - Federal Couragia M/T Mud-Terrain Tire 35x12.50r15 C-ply - 65.6 lbs (35 psi)
- Concerns about balancing reported by a few people.
General Grabber X3
- $212 - 35x12.50r15 C-ply - 75 lbs (35 psi)
Ironman All Country M/T Tire - No 35" at 15"
Milestar Patagonia M/T Mud-Terrain Radial Tire
- $194 - 35x12.50r15 - 64 lbs (?? psi)
- Concerns about street ware on low psi (OEM suggesting high psi required for crowning so center lugs pickup load).
- Ran a set of these, lasted almost 3 years, good enough!
Some Wheel Research (2020)
Notes.
________________________________
[Auto]
________________________________
[FL] Orlando Area
________________________________
[GAME] Inventory and Links
ADVANCE - DON'T HAVE
AMIGA - DON'T HAVE
AMSTRAD CPC - DON'T HAVE
ARCADE - DON'T HAVE
ATARI 7800 - DON'T HAVE
C64 - DON'T HAVE
FANTASY (PC) - DON'T HAVE
MEGADRIVE
- 1000 in 1
- Aladdin (1000 in 1)
- Alien Soldier (1000 in 1)
- Adventures of Batman and Robin (1000 in 1)
- Astebros - Still in Development
- Comix Zone (1000 in 1)
- Contra Hard Corps (1000 in 1)
- Dynamite Headdy (1000 in 1)
- Earthworm Jim (1000 in 1)
- Earthworm Jim 2 (1000 in 1)
- Gunstar Heros (1000 in 1)
- Mega Turrican (1000 in 1)
- Musha (1000 in 1)
- Panorama Cotton (1000 in 1)
- Phantom Gear - Still in Development
- Ranger X (1000 in 1)
- Revenge of Shinobi [PAL] (1000 in 1)
- Ristar (1000 in 1)
- Sonic (1000 in 1)
- Sonic 2
- Sonic 3 (1000 in 1)
- Sonic and Knuckles (1000 in 1)
- Streets of Rage 2 (1000 in 1)
- Strider (1000 in 1)
- Thunderforce 3 (1000 in 1)
- Thunderforce 4 (1000 in 1)
- Turtles the Hyperstone Heist (1000 in 1)
- Xeno Crisis
- ZPF - Still in Development
NDS - DON'T HAVE
NEOGEO MVS + SUPERGUN
- 161 in 1
- Metal Slug - Forsale/Trade
- Metal Slug 2 - Forsale/Trade
NES
- 1000 in 1
- Alwas Awakening - Don't Have
- Batman
- Batman Return of the Joker (1000 in 1)
- Castlevania 3 (1000 in 1)
- Kirbys Adventure (1000 in 1)
- Malasombra - In Dev
- Metal Storm (1000 in 1)
- Micro Mages
- Sky Destroyer (1000 in 1)
- Snake Rattle n Roll
- Vice Project Doom - Don't Have
PC
PGM
- Bee Storm - Don't Have
- Demon Front - Don't Have
- Do Don Pachi - Daioujou - Don't Have
- Espgaluda - Don't Have
- Ketsui - Don't Have
- Kights of Valour - Don't Have
- Kights of Valour 2 Plus - Don't Have
- Martial Masters - Don't Have
- Spectral vs Generation - Don't Have
- The Gladiator - Don't Have
PS1
- Adventures of Little Ralph - Don't Have
- Adventures of Lomax
- Alundra
- Alundra 2
- Castlevania: Symphony of the Night
- Destruction Derby 2
- DoDonPachi - Don't Have
- Harmful Park - Don't Have
- In the Hunt
- Legend of Mana - Don't Have
- Megaman X4
- Megaman 8 - Don't Have
- Rapid Reload (aka Gunners Heaven)
- Street Fighter Alpha 3 - Don't Have
- Tenchi wo Kurau II - Don't Have
PS2
- Capcom Classics Collection Vol 1
- Capcom Classics Collection Vol 2
- God of War
- God of War 2
- Jak and Daxter: The Lost Frontier
- Jak and Daxter: The Precursor Legacy
- Jak 2
- Jak 3
- Metal Slug 4/5 - Forsale/Trade
- Ratchet and Clank
- Ratchet and Clank: Deadlocked
- Ratchet and Clank: Going Commando
- Ratchet and Clank: Size Matters
- Ratchet and Clank: Up Your Arsenal
- Sky Gunner - Don't Have
PS5
- Blazing Chrome - Don't Have
- Ratchet and Clank: Rift Apart
- Teenage Mutant Ninja Turtles: Shredder's Revenge - Don't Have
- Vengeful Guardian: Moonrider - Don't Have
SNES
- 900 in 1
- Aladin (900 in 1)
- Axelay (900 in 1)
- Legend of Zelda
- The Lost Vikings (900 to 1)
- The Magical Quest (900 to 1)
- TMNT 4: Turtles in Time
- Wild Guns - Don't Have
ZX SPECTRUM - DON'T HAVE
________________________________
[HW] FPGA Stuff
This is a very slow burn project to think through my ideal interger ALU vector hardware.
Designed for Xilinx 7 series FPGAs (or later).
The end goal is to build out a neo-vintage console with my kids some day.
Current thoughts are a radical departure from how integer hardware was done in the past.
Others
Boards
- $300, XC7A100T - 250 DSP, 4860 Kb
- $370 (more for 200T), XC7A100T
- $500, XC7K70T - 240 DSP, 4860 Kb
- $550, XC7A200T - 740 DSP, 13140 Kb
- $1000, XC7K160T - 600 DSP, 11700 Kb
- $1100, XC7K325T - 840 DSP, 16020 Kb
- RHSResearch
Example Per DSP Budget
- 7A100T
- 240 DSPs, 11100 SLICEL, 4750 SLICEM (each SLICE is 4 LUTs and 8 flip-flops)
- 46 SLICEL/DSP
- 19 SLICEM/DSP
________________________________________________________________________________________________________________________________
[HW] Ownership
Once upon a time, when you purchased a computer,
it booted into a console for a programming language,
came with a manual with language and hardware documentation.
The consumer owned the machine, was both supported and free to do whatever they wanted to do with it.
Since then others have stepped in to remove personal ownership of the machine and exert policy by restricting your access to the machine via software.
OS vendors act as if they own your machine.
Hardware vendors also act as if they own the hardware.
Signed firmware is an obvious example of this.
Another important example is the lack of exposure of the hardware in user-accessable APIs,
or not being able to run your own binaries.
A large component of what enables this anti-consumer behavior
is an industry which has evolved through amplification of complexity.
The hardware got so needlessly complex that a single individual would have a hard time writting code to interface with the machine.
Thus few can organize any type of counter option, except via things like hurd mentality which often doesn't produce good results.
I'd personally like to see a return of a simple machine.
Something accessable and inexpensive.
One which boots into console with a langauge.
One which can be easily understood and fully interfaced by a single individual.
Think of this as a "hyper-calculator".
________________________________________________________________________________________________________________________________
[HW] Multi-Tasking
Why share?
- Switch with N slots (N is the number of simultaneous programs).
- Human input mux {key, mouse, gamepad, etc}, where input is sent to only the machine with focus.
- Display mux, where program with focus owns screen.
- Display mux with picture in picture for cases where one wants "split screen".
- Mux ownership visible to programs (so they know when to sleep, or not display, etc).
- Audio mixer that physically mixes output from programs, with per-program knobs.
- Input audio mux separate from human input mux.
- Program is a cartride which includes {processors, memory, and flash}.
- No need for most "disk" access, program is persistent in flash.
- Network input is broadcast to all programs, with physical button to enable/disable.
- Network output is accumulated from all programs, with physical button to enable/disable.
Clipboard Doesn't Need An API
- Fixed memory location for 'type' of data as integer, with high bit as 'cooperative lock'.
- Fixed memory location and size for clipboard data.
- Shared by all.
- Nothing more is needed.
________________________________________________________________________________________________________________________________
[HW] 3-Bank Register File?
Thoughts on manual 3-banks of dRAM for a register file.
- Created from distributed RAM (dRAM)
- Either 192 or 96 register configuration
- 192 registers
- Each bank: 64 entry x 3-bit Simple Dual Port (SDP, aka one read, one write) in 4 LUTs
- 18 SLICEM: 18-bit = 6 SLICEMs/bank
- 24 SLICEM: 24-bit = 8 SLICEMs/bank
- 30 SLICEM: 30-bit = 10 SLICEMs/bank
- Likely too many SLICEMs
- 96 registers
- Each bank: 32 entry x 6-bit Simple Dual Port (SDP, aka one read, one write) in 4 LUTs
- 9 SLICEM: 18-bit = 3 SLICEMs/bank
- 12 SLICEM: 24-bit = 4 SLICEMs/bank
- 15 SLICEM: 30-bit = 5 SLICEMs/bank
- 16 SLICEM: 36-bit = 6 SLICEMs/bank
- Each bank direct mapped to DSP input {A,B,C} (except maybe C) for high clocks
- Could have separate store control for all 3 banks
- Complex to write assembly for
- Not all values will need to be in all banks
- And accumulator usage typically won't require stores
- So when DSP to dRAM is not needed, loads or constants could be stored
- Likewise stores (not to register file) can use DSP output (instead of fetching from register file)
- The dRAM stores will need to be filtered through a CLB to mux options
________________________________________________________________________________________________________________________________
[HW] DSP MUX at C
When always using the MUL path, and using a simple 3 banked register file,
there is a clock available to MUX inputs to C due to registering M.
Perhaps a prefered way to do input modifications at high clocks.
- C can have a CLB
(bRAM A)__[>A]__(*)__[>M]__(+)__[>P]
(bRAM B)__[>B]__/ /
(bRAM C)_______(CLB)_[>C]_/
- Could MUX in constants/etc to C
- To avoid needing to burn the register file
________________________________________________________________________________________________________________________________
[HW] Left-Justified
The idea is to always maximize precision by default.
Fixed point numbers are all {-1.0 to <1.0}.
This kind of thinking completely changes everything (as will be seen in later sections).
- Fixed point number convention
MSB.....LSB CONVENTION
=========== ==========
00000000000 0.0 zero (false)
01111111111 <1.0 largest positive
10000000000 -1.0 smallest negative (true)
- Traditional 'unsigned' {0.0 to 1.0} values go {0.0 to -1.0} instead
- Only the signed side has ability to encode the 1.0
- Any 'unsigned' {0.0 to <1.0} values stay positive {0.0 to <1.0}
- Memory is {0.0 to <1.0} accessed (left aligned, instead of right aligned indexing)
- So a 320 entry memory would be accessed {0.0 to 320.0/512.0}, where the 1.0 is the next power of 2 in size
- Using {-0.5 to 0.5} for {-1.0 to 1.0} ranged data
- Then extra 'p=p+p' (accumulator added to itself) to renormalize before final output
Signed MACC
- Designed to work with Xlinix FPGA DSPs
- B: One lower bit-width MUL operand (LSBs zeroed, following left-justify convention)
- A: One medium bit-width MUL operand (LSBs zeroed, following left-justify convention)
- C: One register bit-width ADD operand
- P: One high bit-width accumulator (larger than register file width)
- Showing first a 32-bit proxy, then the actual 48-bit accumulator target configuration
- 12-bit x 15-bit = 27-bit partial product sign extended to 32-bit (proxy)
11111111 11111111 00000000 00000000
fedcba98 76543210 fedcba98 76543210
========-========-========-========
........ ........ ....bbbb bbbbbbbb 12-bit input for MUL
........ ........ ....0111 11111111 2047
........ ........ ....1000 00000000 -2048 (representing -1.0)
........ ........ .aaaaaaa aaaaaaaa 15-bit input for MUL
........ ........ .1000000 00000000 -16384 (representing -1.0)
.....mmm mmmmmmmm mmmmmmmm mmmmmmmm
.....010 00000000 00000000 00000000 -16384 * -2047 = 33554432 (maximum positive output)
.....110 00000000 00000000 00000000 -33554432
pppppppp pppppppp pppppppp pppppppp 32-bit accumulator
sssssmmm mmmmmmmm mmmmmmmm mmmmmmmm sign-extended multiply result
......bb bbbbbbbb bb...... ........ register part used for 12-bit input (MSBs)
......aa aaaaaaaa aaaaa... ........ register part used for 15-bit input (MSBs)
- 18-bit x 25-bit = 43-bit partial product sign extended to 48-bit (target)
22222222 22222222 11111111 11111111 00000000 00000000
fedcba98 76543210 fedcba98 76543210 fedcba98 76543210
========-========-========-========-========-========
........ ........ ........ ......bb bbbbbbbb bbbbbbbb 18-bit input for MUL
........ ........ ........ ......01 11111111 11111111 131071
........ ........ ........ ......10 00000000 00000000 -131072 (representing -1.0)
........ ........ .......a aaaaaaaa aaaaaaaa aaaaaaaa 25-bit input for MUL
........ ........ .......1 00000000 00000000 00000000 -16777216 (respresenting -1.0)
sssssmmm mmmmmmmm mmmmmmmm mmmmmmmm mmmmmmmm mmmmmmmm sign-extended multiply result
......bb bbbbbbbb bbbbbbbb ........ ........ ........ part used for 18-bit input (MSBs)
......aa aaaaaaaa aaaaaaaa aaaaaaa. ........ ........ part used for 25-bit input (MSBs)
......cc cccccccc cccccccc cccccccc cccccc.. ........ part used for 32-bit register file (or ADD)
ssssss.. ........ ........ ........ ........ ........ sign extension for C
........ ........ ........ ........ ......10 00000000 single one bit to setup for rounded accumulation
High Precision Shift Left
- DSP has ability to feed result back into adder at high-precision
- This can be done without any delay
- Enables 'P+P = 2*P = P<<1'
- This provides a framework for mapping back to normalized multiplies,
- Example if we know this won't overflow,
Map 'x*3+x' to '(x*(3/4)+x*(1/4))<<2'
Which takes 2 'x+x' clocks to renormalize
Rounding
Truncation moves towards the smaller value.
Often a series of MADs feeding into an accumulator will start with an add operand of zero.
To setup for rounding, can feed in a 1 bit before the LSB. Showing non-normalized examples below.
- Unsigned logic examples
0.4 + 0.5 = 0.9 -> 0.0
0.6 + 0.5 = 1.1 -> 1.0
1.4 + 0.5 = 1.9 -> 1.0
1.6 + 0.5 = 2.1 -> 2.0
- Signed logic examples
-0.4 + 0.5 = 0.1 -> 0.0
-0.6 + 0.5 = -0.1 -> -1.0
-1.4 + 0.5 = -0.9 -> -1.0
-1.6 + 0.5 = -1.1 -> -2.0
________________________________________________________________________________________________________________________________
[HW] Negatives
The DSP48E1 guide uses a different way of documenting ALUMODE, this is my way.
- For signed 16-bit use {0, -32768} as {0 to 1.0} convention
- fedcba9876543210
================
0000000000000000 ... 0
0111111111111111 ... 32767 (maximum positive)
1000000000000000 ... -32768 (minimum negative)
1111111111111111 ... -1
- For bools use sign bit, so 16-bit is {0:=false,-32768:=true}
- No negate, just 'neg(x) = not(x) + 1'
- No double negate 'd = -a + -b', instead 'd = a + b' then use '-d' later
- No subtract, instead NOT modifiers
- a - b = a + not(b) + 1
- a - b = not(not(a) + b) ... alternative more useful form
- DSP48E1 when using Multiplier (instead of the A:B high precision add)
- X options
- P (recirculate past result)
- M (multiplier partial result)
- 0 (zero)
- Y options
- C (input)
- M (multiplier other partial result)
- ~0 (all ones)
- 0 (zero)
- Z options
- P (recirculate past result)
- C (input)
- 0 (zero)
- Useful input configurations
Z XY
= ==
0 + 0 (zero)
0 + P (nop)
0 + C (move)
0 + M (multiply)
C + M (multiply add)
P + M (multiply accumulate)
P + C (accumulate)
P + P (high precision double result, aka shift left 1)
- ALUMODE
- 0: Z +(X+Y+CIN) ... add
- 1: (~Z)+(X+Y+CIN) ... -Z+(X+Y+CIN)-1 ... if CIN=1 then get -Z+(X+Y)
- 2: ~( Z +(X+Y+CIN)) ... neg output
- 3: ~((~Z)+(X+Y+CIN)) ... sub, 'Z-(X+Y+CIN)'
Example: Parabolic Sqrt (Left-Justified Logic)
- Parabolic sqrt(x) estimation
- Using {0 to MIN_NEGATIVE} as {0.0 to -1.0} convention
- Result using positives would be '2*x-x*x'
- But want negatives so '2*x+x*x'
- Highest precision
- p=x
- p+=p ..... Have 5-bit guard so this won't overflow
- p+=x*x ... This gets 18-bit * 25-bits of precision for multiply
- Fast, lower precision
- p=x-(-1.0*x) ... The 'x' in the multiply is 25-bits of precision
- p+=x*x ......... This gets 18-bit * 25-bits of precision for multiply
Example: Simple Filter Kernel (Left-Justified Logic)
- Could replace a gaussian in some cases
- Using {0 to MIN_NEGATIVE} as {0.0 to -1.0} convention
- Result using positives would be '(1-x*x)^2'
- But want negatives so '0-(-1+x*x)^2'
- Highest precision
- s=p=-1+(x*x) ... This gets 18-bit * 25-bits of precision for multiply, need high latency path though store
- p=0-(s*s) ...... Accumulator 'P' doesn't have direct path into multiplier, so must load
________________________________________________________________________________________________________________________________
[HW] Divide
Strategy for doing divides in a left-justified normalized world is a critical foundation for many things.
- Divide as in doing 'y=x/a'?
- Where 'x' and 'a' are {-1.0 to <1.0} ranged
- And typically 'a' would be {-1.0 to 0.0} ranged
- Instant problem with 'y=x/a' in this case, as 'a' would always grow the 'abs(y)' beyond the {1.0}
- Example, if 'x=-1.0' then 'abs(y)' is '1/a' so 'a=1/256' for example would yield 'abs(y)=256'
- So really want to do 'y=x/(a*s)' where 's' is the expected maximum useful value of 1/a
- Sets the effective minimum value of 'a' before the output gets clamped
- Anything 'a<1/s' would result in 'abs(y)=1.0' clamped result
Iterative Solution
- This in the end will get expressed as a binary search for the solution 'y'
- Which implies computing the inverse to test the solution: 'x==y*a*s'
- Since the HW cannot express 's>1.0' values this gets converted to 'x*(1/s)==y*a' where 's>1.0'
- Note since 'x' is an input, the 'x*(1/s)' gets factored out of the search iteration
- The search is thus for 't==y*a' where 't=x*(1/s)'
- Note this has almost the same form as a binary search for 'sqrt(x)' which would be 't==y*y' test with 't=x'
... WORK IN PROGRESS ...
Making /0.0 Result in -1.0
- The 'a' would be {-1.0 to 0.0} ranged, and don't want a sign flip on the 'x/a' based inputs
- So this is realy 'y=x/(-s*a)' or 'x=-s*a*y' or 'x*(-1/s)==y*a' for testing
- Actually want 'x*(1/s)==-(y*a)' instead, so the CMP that was a SUB becomes an ADD
- Since this is a signed normalized machine, -1.0 functions as INF
- ?????????????????????????????????????????????????????????????????????????????????????????????
- Start the search at 'y=-1.0' and conditionally move towards 'y=0.0'
- The test to advance 'y' at the interval will be 'x*(1/s)>=-(y*a)'
- Or more specifically '(x*(1/s))+(y*a)>=0'
What About RCP
Same logic, just set 'x=-1.0' and pick an acceptable scaling factor for 's'.
________________________________________________________________________________________________________________________________
[HW] Variable Bit-Width MEM
Word, Half, Byte, and Nibble
Simplest form of compression: variable bit-width loads.
- Variable bit width loads are left aligned (new) instead of right aligned (traditional)
- Has an addressing querk: use highest possible address for a given size (to avoid extra LUT driving MUX)
- Requires 8 SLICEs total (for one 32-bit input)
- Requires a one clock pipeline stage
- Requires 3-bit mask (drives inputs to MUX) from decoded instruction for sizing
- Could be super important hardware, because FPGAs are highly memory constrained devices!
- Load permutations, where '.' is a zero
11111111111111110000000000000000 ADR
fedcba9876543210fedcba9876543210 hbn
================================ ===
vutsrqponmlkjihgfedcba9876543210 111
vutsrqponmlkjihg................ 111
vutsrqpo........................ 111
vuts............................ 111
rqpo............................ 110
nmlkjihg........................ 101
nmlk............................ 101
jihg............................ 100
fedcba9876543210................ 011
fedcba98........................ 011
fedc............................ 011
ba98............................ 010
76543210........................ 001
7654............................ 001
3210............................ 000
================================
xxxx............................ 4x 8:1 MUX (8 LUTs = 2 SLICEs)
hbn - address bits (direct map to mux)
....xxxx........................ 4x 8:1 MUX (8 LUTs = 2 SLICEs)
hb. - address bits
..0 - 4-bit nibble (output zero)
..1 - not 4-bit nibble
........xxxxxxxx................ 8x 4:1 MUX (8 LUTs = 2 SLICEs)
h. - address bit
.0 - 4-bit nibble or 8-bit byte (output zero)
.1 - 16-bit half or 32-bit word
................xxxxxxxxxxxxxxxx 16x 2:1 MUX (8 LUTs = 2 SLICEs, using 5 inputs to 2 output LUTs)
0 - not 32-bit word (output zero)
1 - 32-bit word
- Store permutations, where '.' is a zero (ignored, because using byte write mask)
11111111111111110000000000000000 ADR
fedcba9876543210fedcba9876543210 hb byte write mask
================================ == ===============
vutsrqponmlkjihgfedcba9876543210 11 1111
vutsrqponmlkjihg................ 11 1100
vutsrqpo........................ 11 1000
........vutsrqpo................ 10 0100
................vutsrqponmlkjihg 01 0011
................vutsrqpo........ 01 0010
........................vutsrqpo 00 0001
================================
xxxxxxxx........................ Direct map (no MUX)
........xxxxxxxx................ 8x 2:1 MUX (4 LUTs = 1 SLICEs, using 5 inputs to 2 output LUTs)
h - address bit
................xxxxxxxx........ 8x 2:1 MUX (4 LUTs = 1 SLICEs, using 5 inputs to 2 output LUTs)
h - address bit
........................xxxxxxxx 8x 4:1 MUX (8 LUTs = 2 SLICEs)
hb - address bits
________________________________________________________________________________________________________________________________
[HW] XOR Offseting
Often don't want to burn an adder for 'base+offset', doing XOR instead could be useful.
OFF 000 001 010 011 100 101 110 111 0 1 2 3 4 5 6 7
BAS --- --- --- --- --- --- --- --- - - - - - - - -
000 | 000 001 010 011 100 101 110 111 0 | 0 1 2 3 4 5 6 7 ---> zero BAS works like ADD
001 | 001 000 011 010 101 100 111 110 1 | 1 0 3 2 5 4 7 6 ---
010 | 010 011 000 001 110 111 100 101 2 | 2 3 0 1 6 7 4 5 ^
011 | 011 010 001 000 111 110 101 100 -> 3 | 3 2 1 0 7 6 5 4 | the rest provide various reordering patterns
100 | 100 101 110 111 000 001 010 011 4 | 4 5 6 7 0 1 2 3 |
101 | 101 100 111 110 001 000 011 010 5 | 5 4 7 6 1 0 3 2 v
110 | 110 111 100 101 010 011 000 001 6 | 6 7 4 5 2 3 0 1 ---
111 | 111 110 101 100 011 010 001 000 7 | 7 6 5 4 3 2 1 0 ---> ~0 BAS inverts the order of OFF
________________________________________________________________________________________________________________________________
[HW] Port Conflicts
- Reusing ALU P accumulator as an argument(s), leaves open 1 or more register file read port(s) for other usage
- The dRAMs (for register file) have both a regular output, and a registered output, and the register has a write enable,
so in theory if there is a post-read pipeline stage (such as nibble/byte/half/word extraction) reusing the registered output,
it might be possible to use a non-registered read, although this might result in lower peak clocks
- A direct operand mapped manual multi-port register file (via separate dRAMs) provides multiple store ports,
which if not all are needed, could be open for other usage,
as typically a result might not need to be reused in all operand slots,
and note the address lines are also free to be changed
________________________________________________________________________________________________________________________________
[HW] Instruction Palette
Core Challenges
- When ALU density gets high, also need large programs to do interesting stuff (see GPU trends)
- Don't want to burn much RAM for instructions, want some forms of compression
- Latency mitigation often involves loop unrolling
- Sometimes it will be same set of instructions with a different window of registers
- Sometimes it will be same set of instructions with different constants (compute divide or sqrt, etc)
Suggests an instruction palette would be useful.
Instruction provides a pointer into a palette of instruction data.
Can thus use the rest of the bits for constants.
Or alternatively reference constants instead of instruction data.
Register Operand Compression?
- Examples
20-bits : 5-bit x 4 {P,A,B,C}
20-bits : 4-bit (16-reg window) x 4 {P,A,B,C} = 16-bit + 4-bit offset (2 register granularity)
19-bits : 4-bit (16-reg window) x 4 {P,A,B,C} = 16-bit + 3-bit offset (4 register granularity)
18-bits : 4-bit (16-reg window) x 4 {P,A,B,C} = 16-bit + 2-bit offset (8 register granularity)
16-bits : 3-bit ( 8-reg window) x 4 {P,A,B,C} = 12-bit + 4-bit offset (2 register granularity)
15-bits : 3-bit ( 8-reg window) x 4 {P,A,B,C} = 12-bit + 3-bit offset (4 register granularity)
Needs more thought ...
________________________________________________________________________________________________________________________________
[HW] Saturating Integer
Likely too complex for FPGA.
- Working example for 16-bit machine
- DSP output {MSB guard bits, 16-bit output, discard bits LSB}
- Standard signed saturation (32 terms of overflow guard area)
guard
|||||fedcba9876543210
======---------------
-1048576 = 100000000000000000000 - Lowest negative before saturate fails
-32769 = 111110111111111111111 - Underflow
-32768 = 111111000000000000000
-32767 = 111111000000000000001
======---------------
32766 = 000000111111111111110
32767 = 000000111111111111111
32768 = 000001000000000000000 - Overflow
1048575 = 011111111111111111111 - Highest positive before saturate fails
======---------------
- 5-bits guard + 1-bit of MSB from 16-bit result region
- 6:1 LUT provides 'out-of-bounds' detection
- Requires 8 5:2 LUTs to saturate 16-bit output
- {2-bits output, 1-bit out-of-bounds, 1-bit saturate enable, 1-bit MSB of guard} inputs to LUT
- This is thus 2 levels of LUT deep
________________________________________________________________________________________________________________________________
[HW] PIMD
Pipelined Instruction Multiple Data?
Network of cores, where the instruction flows through the network (PIMD),
instead of being applied to the network at the same time (SIMD).
In the most simple network, a line, reductions become linear time (vs log time with SIMD),
but with high latency from start to finish.
First problem with PIMD is that ALUs are also pipelined,
so would need some way to manage that delay and still have useful execution.
Don't want to use memory at each ALU to buffer a series of instructions.
One alternative is to replay the instruction locally, but run through a series of registers.
So reductions are always vectorized (aka multi-component).
Not well thought out ...
Big Program Small Memory
As ALU density increases, natually
the quanity of local memories increase, and the size of those memories decrease.
It becomes possible to run unique program/node only if the program is tiny.
There would be a desire to interleave the program across the memories,
to enable large programs to be executed.
This also has a secondary goal, to amortize memory access for the program across all the memories.
Thus if the machine had N nodes, instructions would only be fetched 1/N times per node during execution.
Starting with the simplest of networks,
a directional torus which is interleaved so there is no long return path.
Path worst case path length is 2x the node spacing.
Showing a simplified example of an 8 node machine in the horizontal axis.
,-------. ,-------. ,-------. ,--.
a h b g c f d e
`--' `-------' `-------' `-------'
Which looks like this logically.
a -> b -> c -> d -> e -> f -> g -> h
^ |
`----------------------------------'
De-pipelined start example on clock 0.
Steady state pipelined execution example on clock 8.
Example in octal.
Each node pulls the instruction to execute from the instruction previously executed by the logically left neighbor.
With exception that node 'A' pulls it's instruction from prior instruction latch value of node 'H' (it's left neighbor).
Each clock the nodes read the instruction latch value from the logically left neighbor.
And the latch value is updated on the 8th clock cycle.
Taking the a read port access to the node's tiny local memory.
Note for each line of 8 instructions the instruction stream is actually backwards.
INSTRUCTION LATCH INSTRUCTION EXECUTE
clk A B C D E F G H A B C D E F G H
=== == == == == == == == == == == == == == == == ==
0 07 06 05 04 03 02 01 00 <-- 8 instructions latched every 8 clocks
1 07 06 05 04 03 02 01 00
2 07 06 05 04 03 02 01 00
3 07 06 05 04 03 02 01 00
4 07 06 05 04 03 02 01 00
5 07 06 05 04 03 02 01 00
6 07 06 05 04 03 02 01 00
7 07 06 05 04 03 02 01 00
8 17 16 15 14 13 12 11 10 07 06 05 04 03 02 01 00 <-- 8 instructions latched every 8 clocks
10 17 16 15 14 13 12 11 10 07 06 05 04 03 02 01
11 17 16 15 14 13 12 11 10 07 06 05 04 03 02
12 17 16 15 14 13 12 11 10 07 06 05 04 03
.. ... ...
This extends to 2D directional torus quite easily.
For an 8x8 node example,
64 new instructions would be latched on every 64th clock cycle.
Every 8 clock cycles the instruction latch would be pulled from the vertical neighbor.
Noticed though that instruction decode gets expensive, probably don't want to replicate the decode,
instead rather fanout the decoded data, so perhaps not useful ...